Connecting to AWS S3
Before you begin, learn how to Connect Data Sources in Canner Enterprise.
Step 1: Create data sources
You can create a data source through the following two operations. The first is to click the "+" button on the sidebar Data Source or click the Create a Data Source button on the Overview page to create.
Step 2: Set connection information
In the pop-up form, fill in and set the connection information, and click Submit to send.
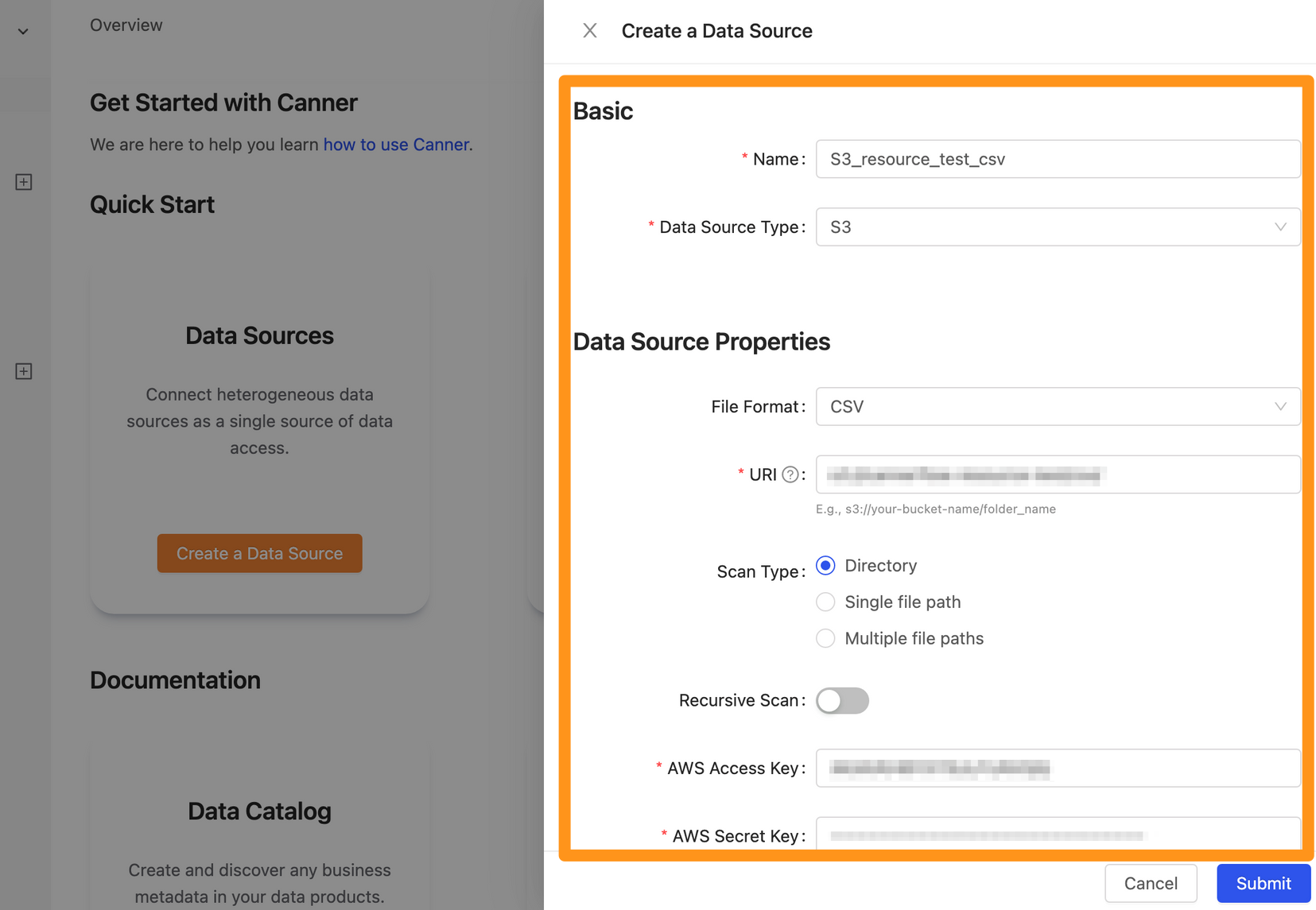
Basic
- Name: The display name of the database in Canner Enterprise, which can be modified later.
- Data Source Type: Database type, please select
S3.
Data Source Properties
###File Format Each data source of Canner Enterprise can only link one file format, and please select a Canner Enterprise supported file format you want to link here. For example, if you choose to link a file in CSV format, even if there are files in multiple data formats, including JSON, Excel, CSV, etc., under the specified path of S3, the system will only link the CSV file.
URIs
Fill in the path of the AWS S3 bucket you want to connect.
The path format is: s3://<bucket-name>/<storage-root>
If the URI you fill in has special characters such as :?#[]@!$&'()*+;, the system will occur an error message. Please note that your bucket or file name cannot contain these characters.
Scan Type
1. Directory
The system will link all specified format files in your path directory. Please fill in the path of the folder you want to select in URI according to your folder structure and the following two link situations.
Example file structure:
Superstore/
├─ Orders/
│ ├─ Orders_2014.csv
│ ├─ Orders_2015.csv
├─ People/
│ ├─ People_East.csv
│ ├─ People_North.csv
│ ├─ People_South.csv
│ ├─ People_West.csv
Link scenario A. Each file under the specified path is an independent Table Link to Directory under URI
s3://my-bucket/Superstore/Orders. After the connection is successful, this source will have two tables,Orders_2014andOrders_2015, in Canner Enterprise.
Link scenario B. Each folder under the specified path is an independent Table Link to Directory under URI
s3://my-bucket/Superstore. After the connection is successful, this source will have two tables,OrdersandPeoplein Canner Enterprise.cautionThis scenario requires that all files in the folder have the same format and schema.
Recursive Scan
If there are folders in the specified path directory of your link, and you want all the folders to be queried in Workspace after the link is successful, you can check this option.
2. Single file path
The system will link to a single file at the path you specify. Fill in the file path of the file you want to select in URI.
Example file structure:
Superstore/
├─ Orders/
│ ├─ Orders_2014.csv
│ ├─ Orders_2015.csv
Example: link URI
s3://my-bucket/Superstore/Orders/Orders_2014.csvfile. After the connection is successful, this source will have a tableOrders_2014in Canner Enterprise.
If you select Excel as the File Format, you can only use the Single file path method to link files. Please fill in the link path of a single file, and the system will parse each worksheet (Sheet) in the Excel file into each Table.
3. Multiple file paths
The system will link all specified format files in your path directory, and you can explicitly select include/exclude specific files and then integrate into a single Table.
cautionThis usage requires that all the file formats and schemas of your include are the same.
In Basic URI, fill in the path of the folder directory you want to specify, and then continue to set the folder path of selected files to be included or excluded.
- Include file paths: List the file paths you want to link under the Basic URI (support wildcard (
*), such as/<folder-name>/*.csv) - Exclude file paths: List the file paths you want to exclude under Basic URI (support wildcard (
*), such as/<folder-name>/*.csv)
Example file structure:
Superstore/
├─ 2021/
│ ├─ Orders_2021.csv
│ ├─ Orders_history.csv
│ ├─ People_2021.json
│ ├─ .metadata
├─ 2022/
│ ├─ Orders_2022.csv
│ ├─ People_2021.json
│ ├─ .metadata
Example: Link to Directory under Basic URI
s3://my-bucket/Superstore. Include file paths: set/2021/Orders_2021.csv/2022/Orders_2022.csvExclude file paths: Set/2021/Orders_history.csvAfter the connection is successful, this source will have aSuperstoreTable in Canner Enterprise, and the content of this Table is the integration of/2021/Orders_2021.csv/2022/Orders_2022.csvtwo files.
###AWS Access Key & Secret Key AWS user's access key, please refer to [AWS - Manage IAM User's Access Key](https://docs.aws.amazon.com/zh_tw/IAM/latest/UserGuide/id_credentials_access- keys.html)
S3 Endpoint
This item is for use if you want other repositories compatible with S3. If you want to know how to use it in detail, please get in touch with Canner Enterprise Support.
###File Format Details import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem';
Step 3: Complete the build
After Submitting, the S3 data source will show up in the sidebar in a few moments, and you can click to enter the data source details page.