運用工作區作為您的資料工作中心
在此教程中,您會了解如何使用 Canner Enterprise 的 Workspace 工作區與團隊人員協作進行資料調用工作。
在開始本教程之前,您會需要先完成在 Canner Enterprise 中連結資料來源。
工作區(Workspace)是 Canner Enterprise 中主要的資料調用與應用中心,您可以至工作區概觀了解更多工作區設計概念以及功能細節說明。
新增工作區
您可以透過以下兩種操作來建立資料來源,第一種為點擊側欄 Workspace 的 “+” 按鈕,或是點擊 Overview 頁面中的 Create a Workspace 按鈕來建立。
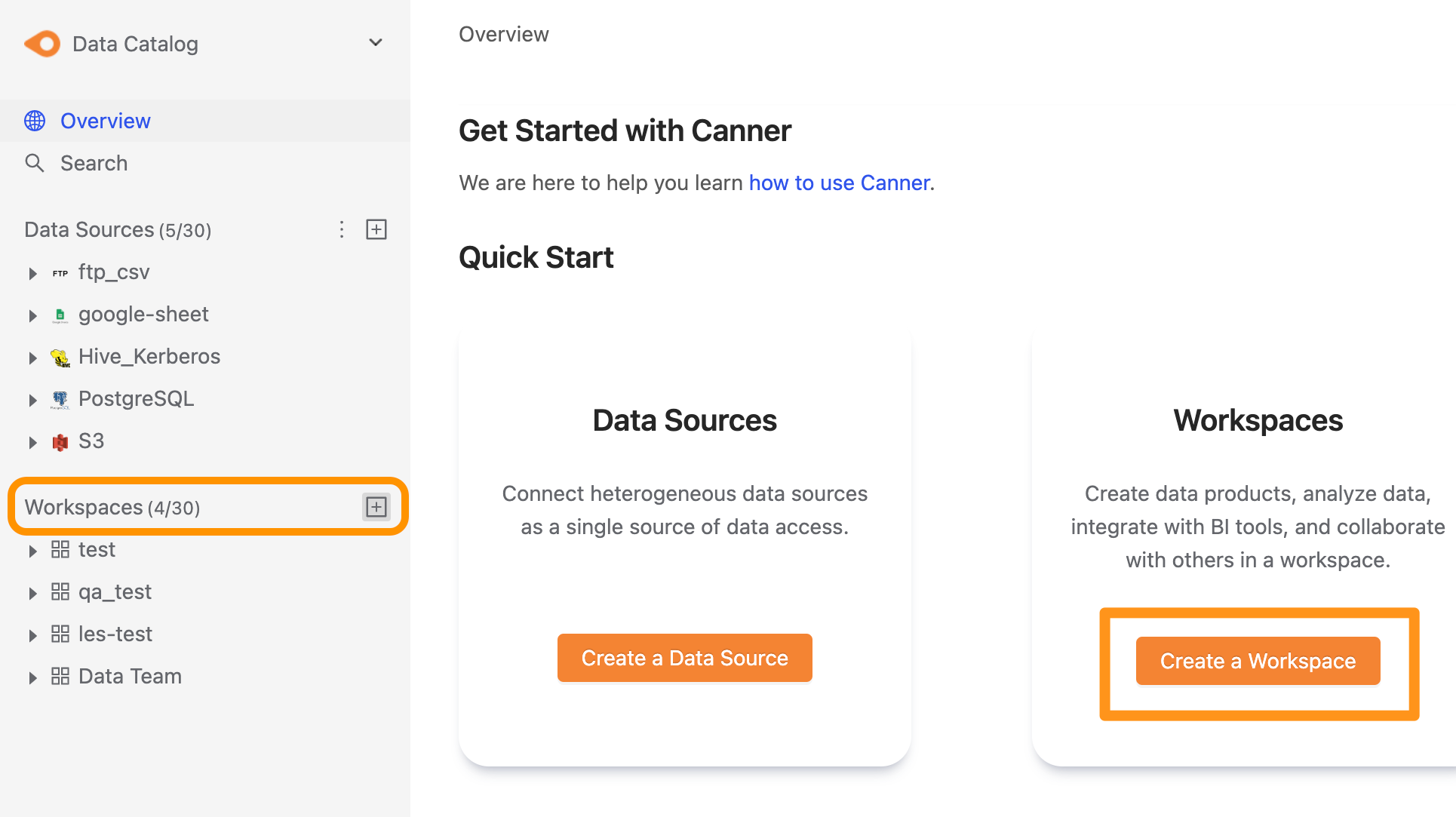
點擊建立後,彈出視窗,可以在此設定工作區的名稱。
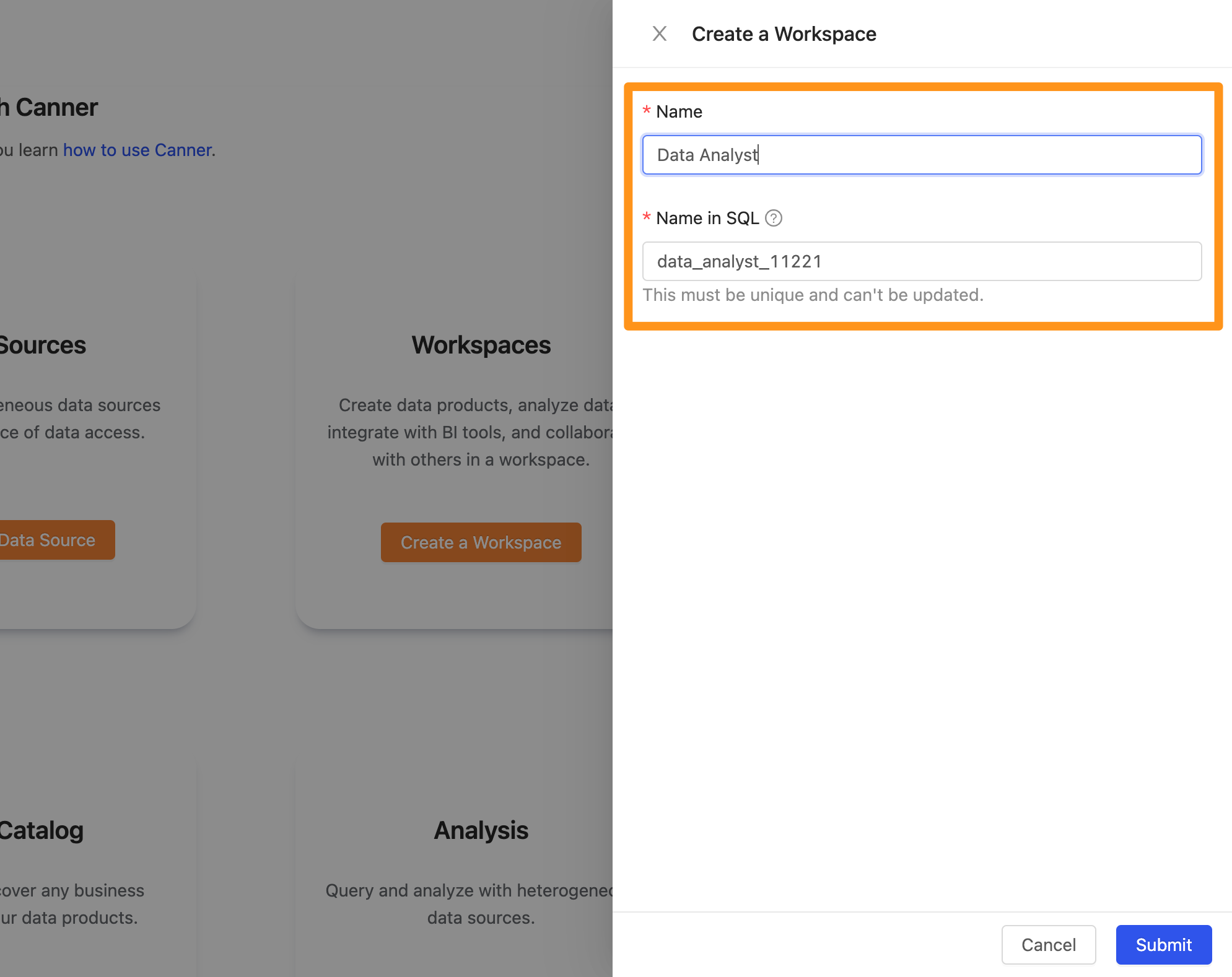
- Name:中輸入您這個工作區的名稱
- Name in SQL: 自動產生一個獨立的 ID。用於透過 API / Driver / PostgreSQL Wire Protocol 連結此工作區時所需輸入的資訊。
點擊 Submit 建立完成後,在側欄中可以看到該工作區中,點擊後可前往工作區畫面如下圖。
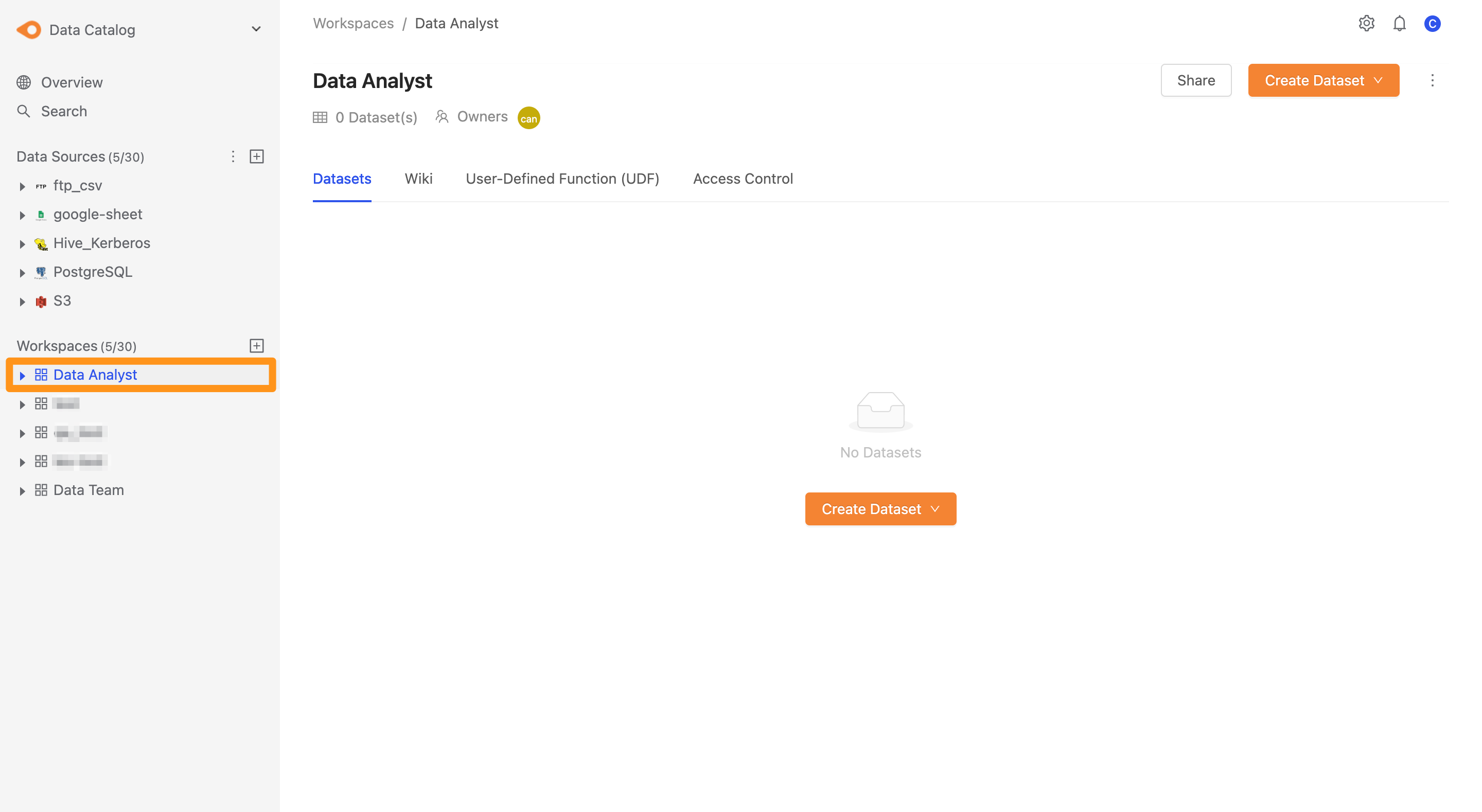
將團隊成員加入工作區
進入工作區並切換到 Access Control 頁面。
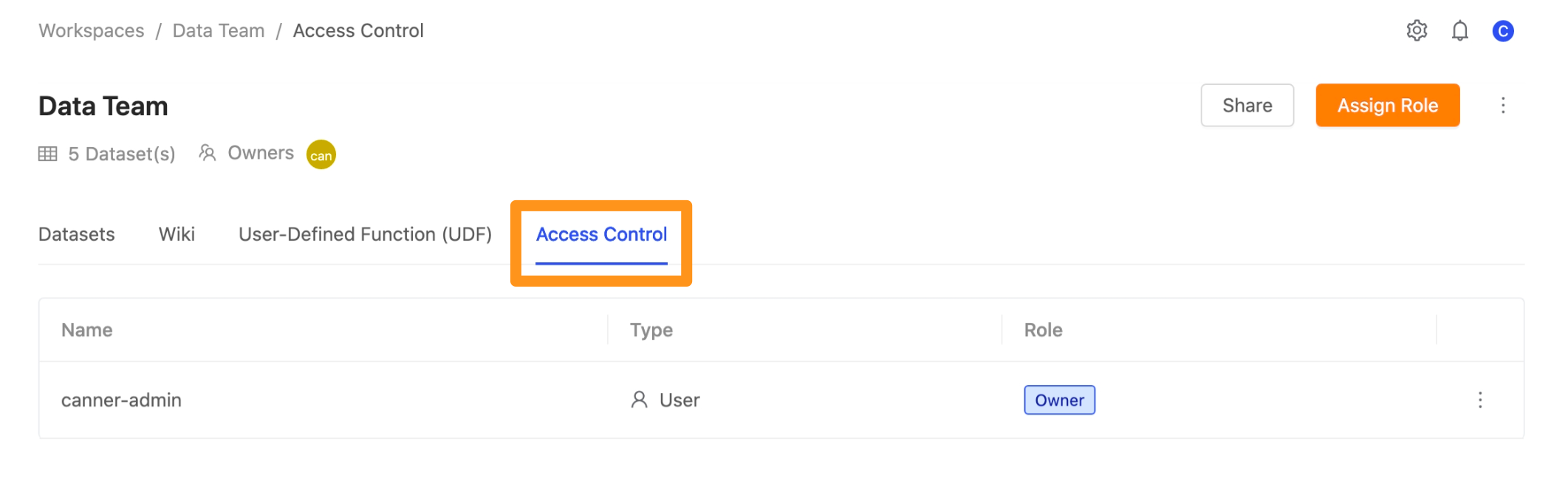
點擊 Assign Role 按鈕,畫面彈出視窗,點擊 Identity 及 Role 展開下拉選單,可以於此加入團隊成員並且設定其角色權限。
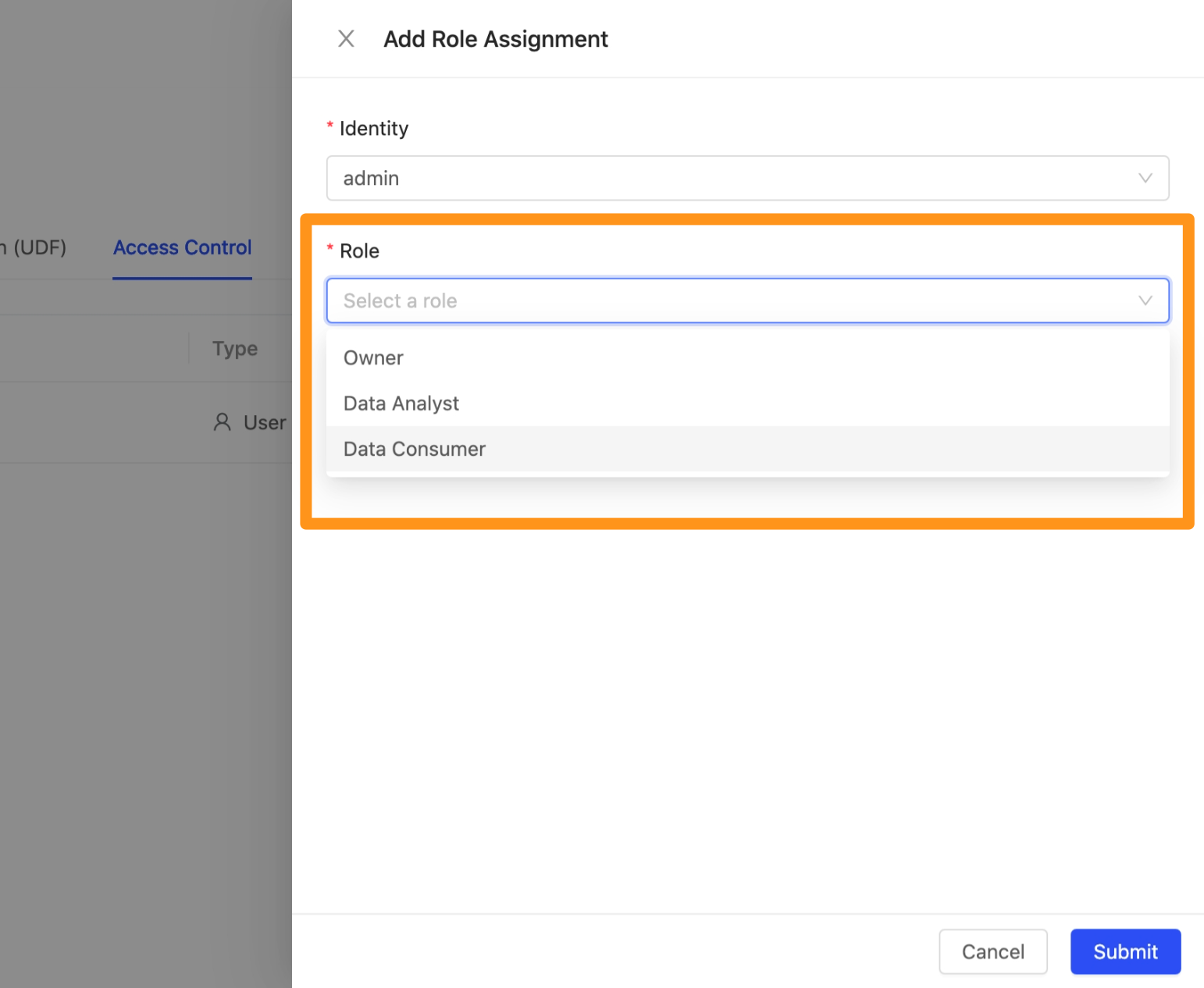
- 【Identity】 選擇您要加入的特定使用者或是群組;
- 【Role】 選擇該使用者或群組在此工作區中的權限角色。
使用工作區 wiki 紀錄工作筆記
將所有團隊成員加入後,切換到 Wiki 分頁,您的團隊可以在此建立多個 Wiki Page ,用 Markdown 方式紀錄一些資料工作的筆記,如:
- 開會討論紀錄
- 演算法研究與討論
- 分析過程紀錄
- 結果探討與追蹤 依照不同團隊能夠有不同的用法。
匯入資料至工作區
接著,您可以開始在工作區中調用來自不同資料來源的資料,再視需求處理運算後輸出。剛建立的工作區不會預設加入任何資料,要先由Owner或Data Analyst角色成員至工作區中並切換到 Datasets分頁來匯入要調用的資料。
方法 1: 從資料來源匯入
Step 1: 進入工作區頁面
在 Datasets 分頁中,擊 Create Dataset 按鈕。點擊後會出現下拉選單,選擇 Create a Table 按鈕。
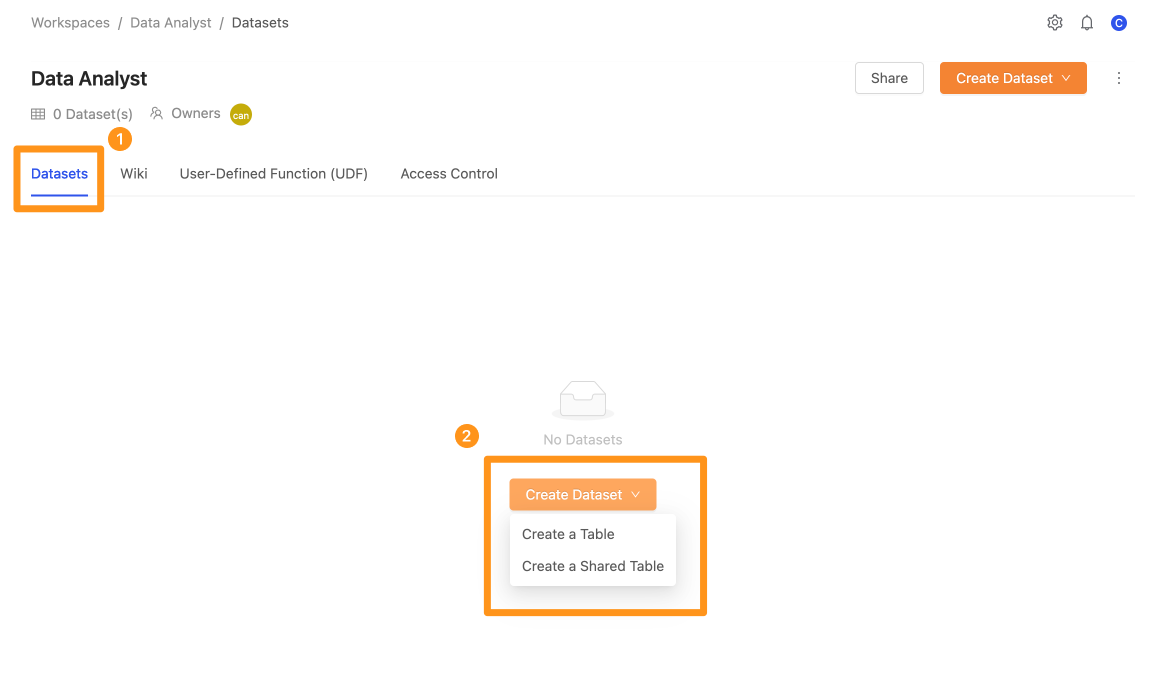
Step 2: 設定從資料來源匯入資料
選擇 Create a Table 按鈕,畫面會出現此視窗。
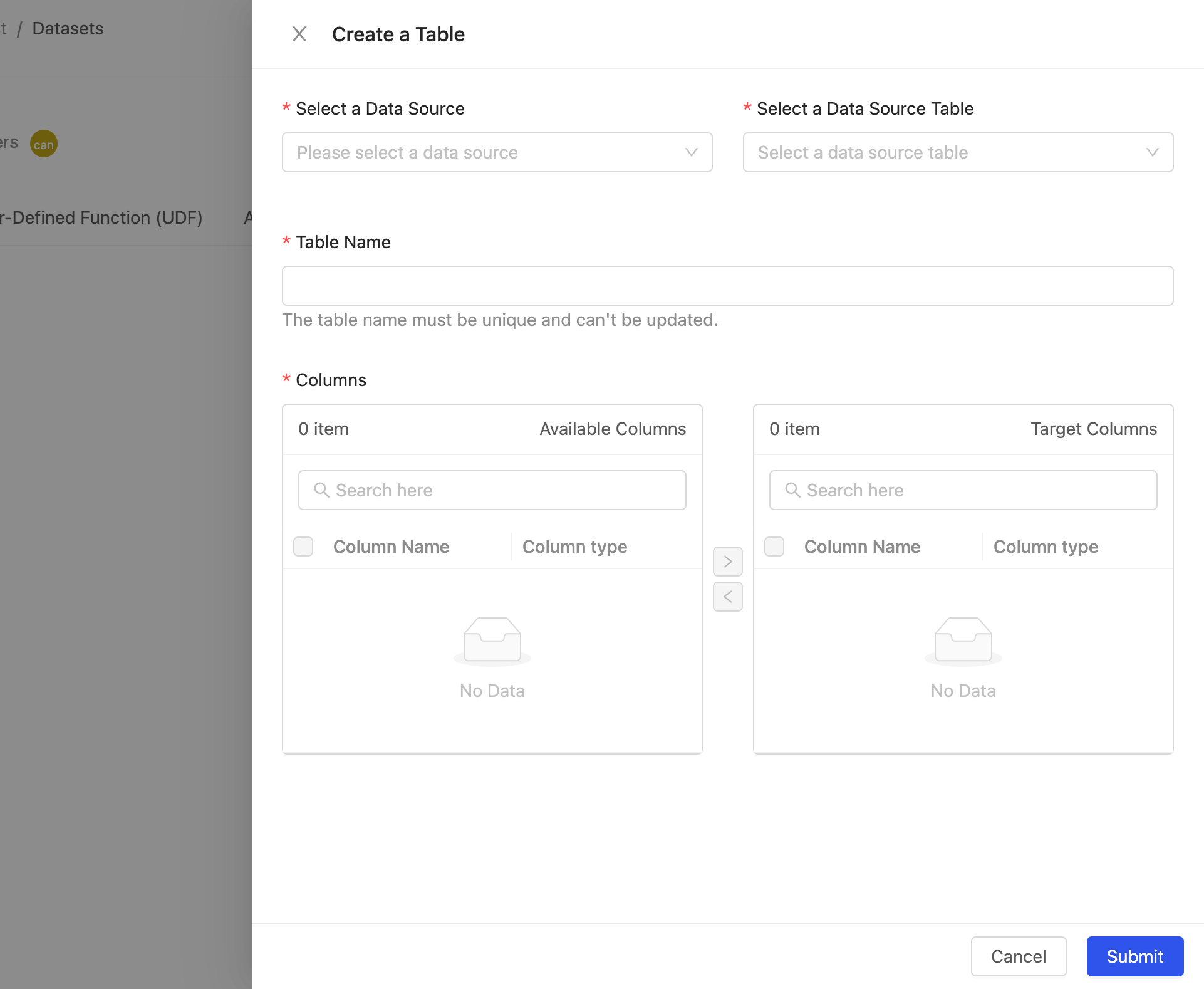
您可以在此選擇要匯入哪個資料來源及其資料表與欄位
- Select a Data Source : 選擇資料來源
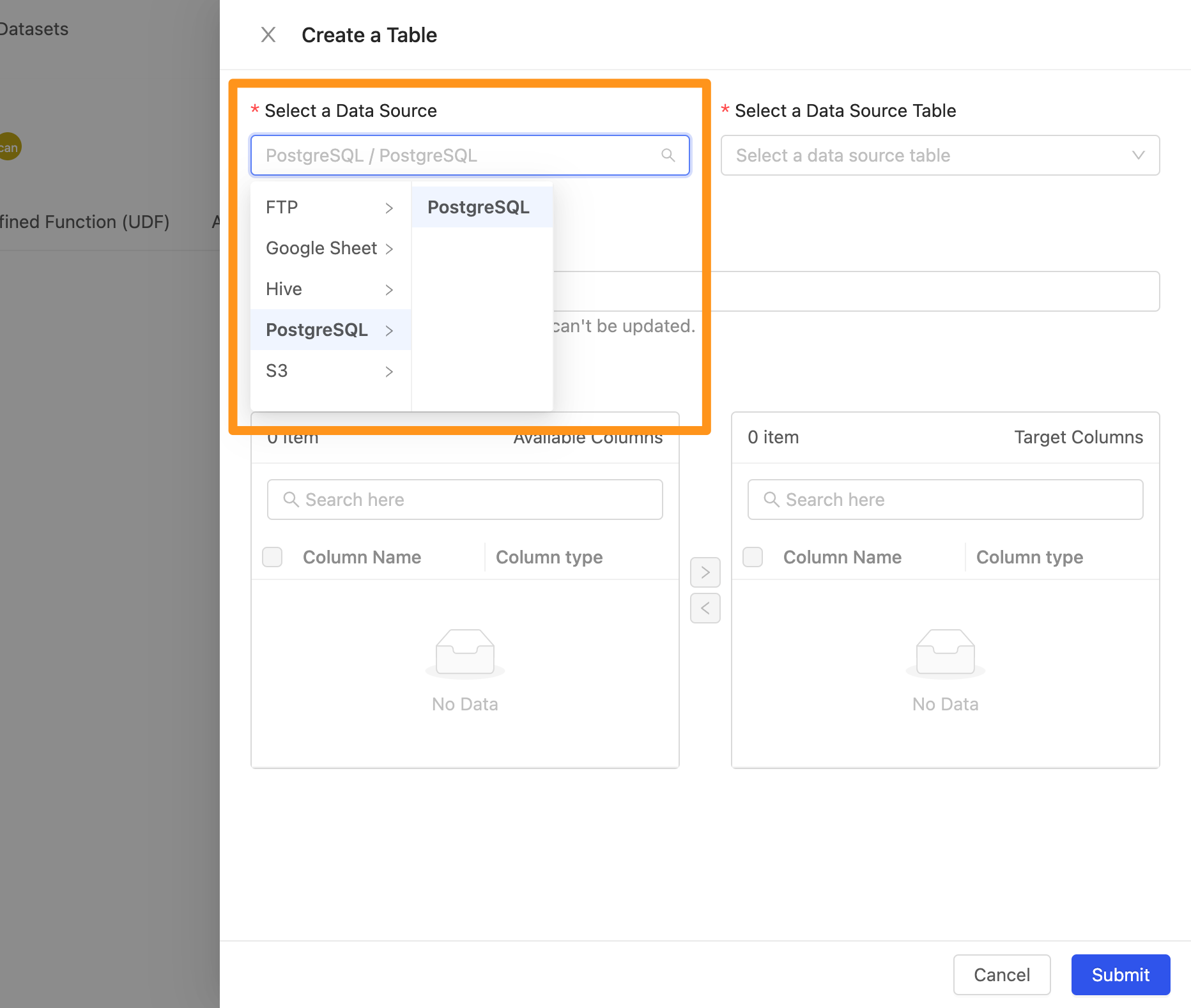
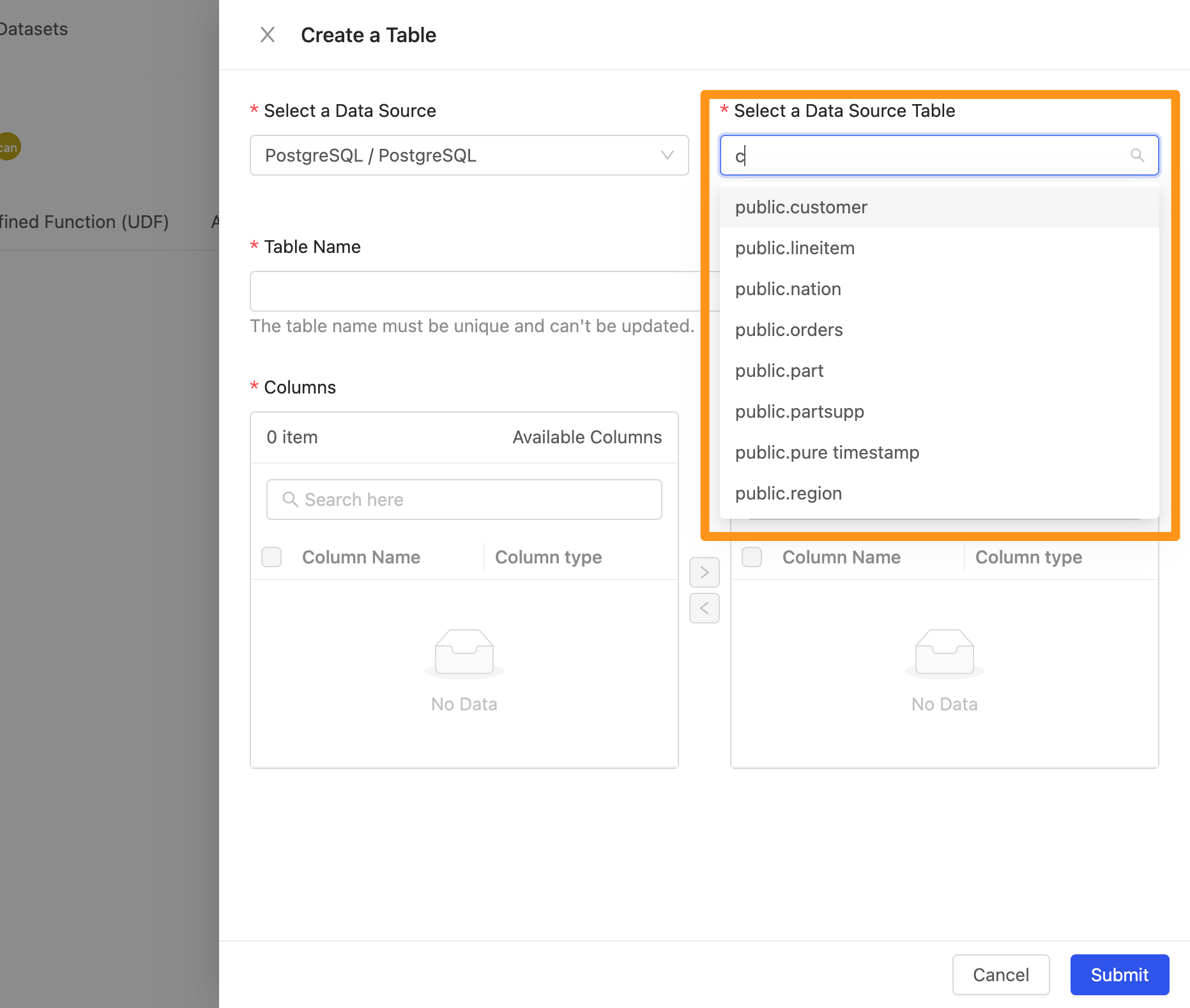
- Select a Data Source Table : 選擇在此資料來源中的 Table,在此你可以透過選單瀏覽也可以輸入關鍵字來查詢要匯入的 Table 名稱
- Table Name : 新增 Table 的時候,系統會以資料表的名稱自動產生出一個唯一值的名稱,以避免 table 在名稱上面與其他的命名重複。
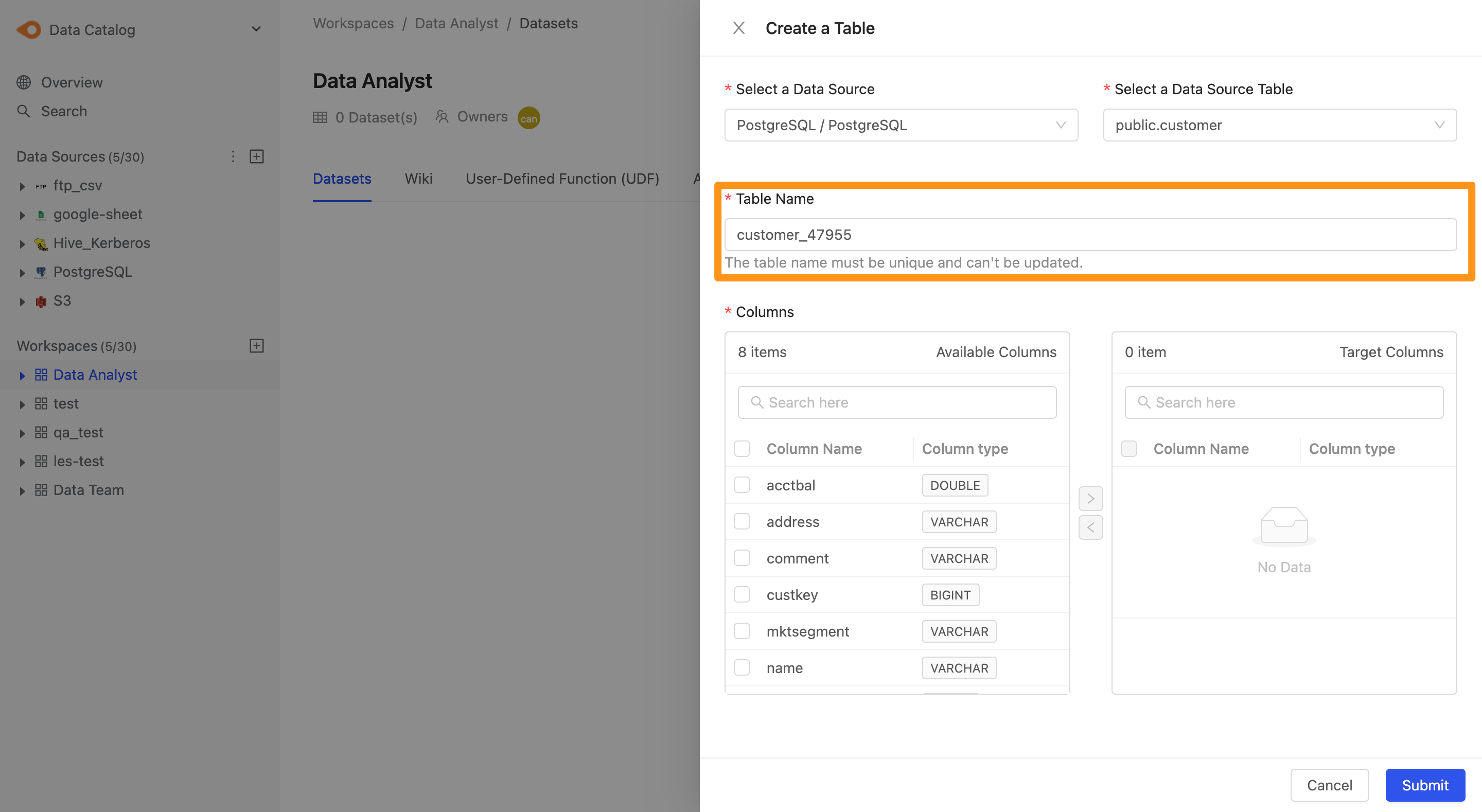
- Columns : 選擇欄位,左邊 Available Columns 代表目前此 Table 有的欄位,右側 Target Column 代表要匯入工作區中的欄位,你可以透過
>與<來選擇要將哪些欄位加入及移除。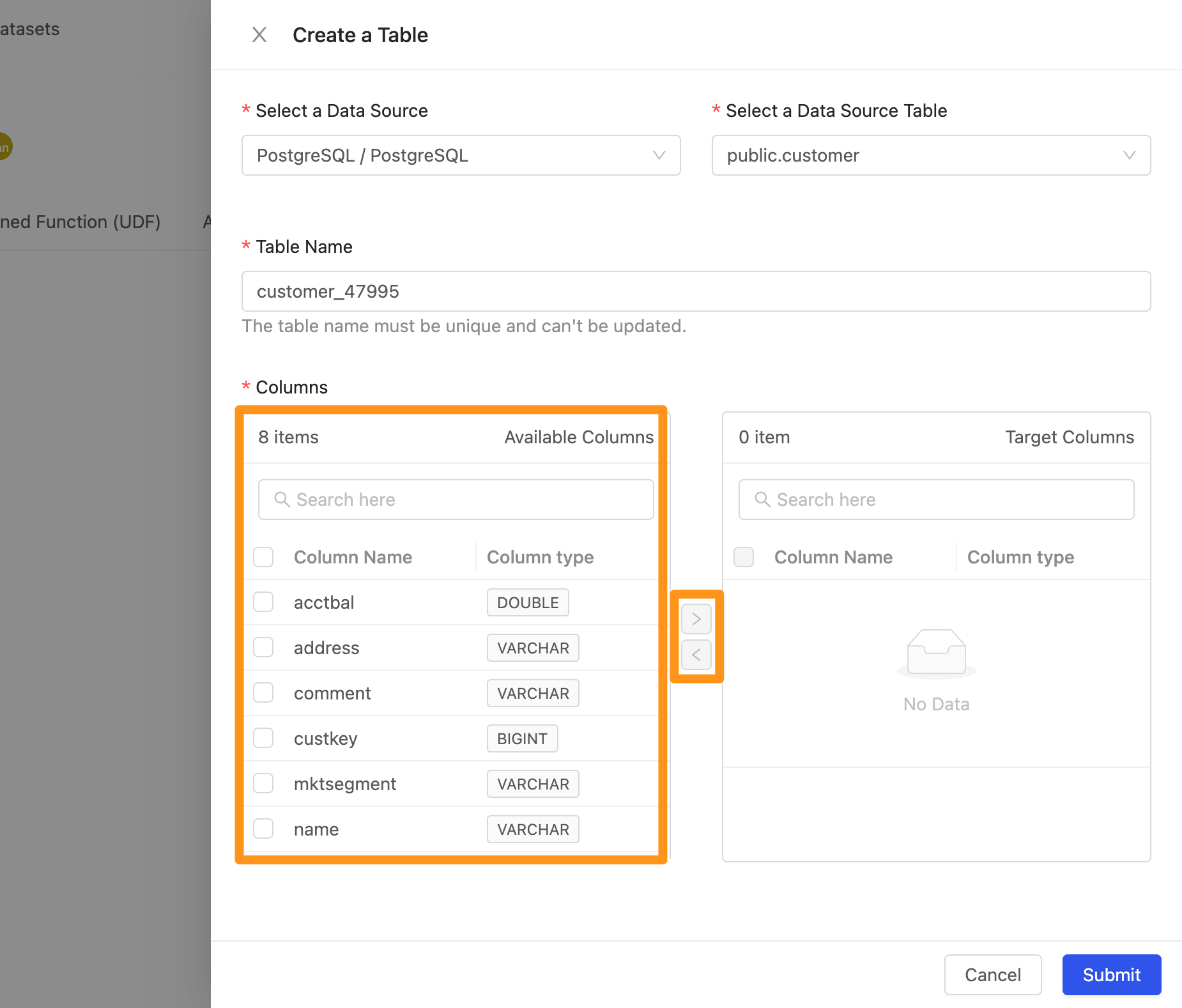
- 選取欄位,點擊 >,該 Column 會移動到右側,代表要此為要匯入工作區的資料欄位。
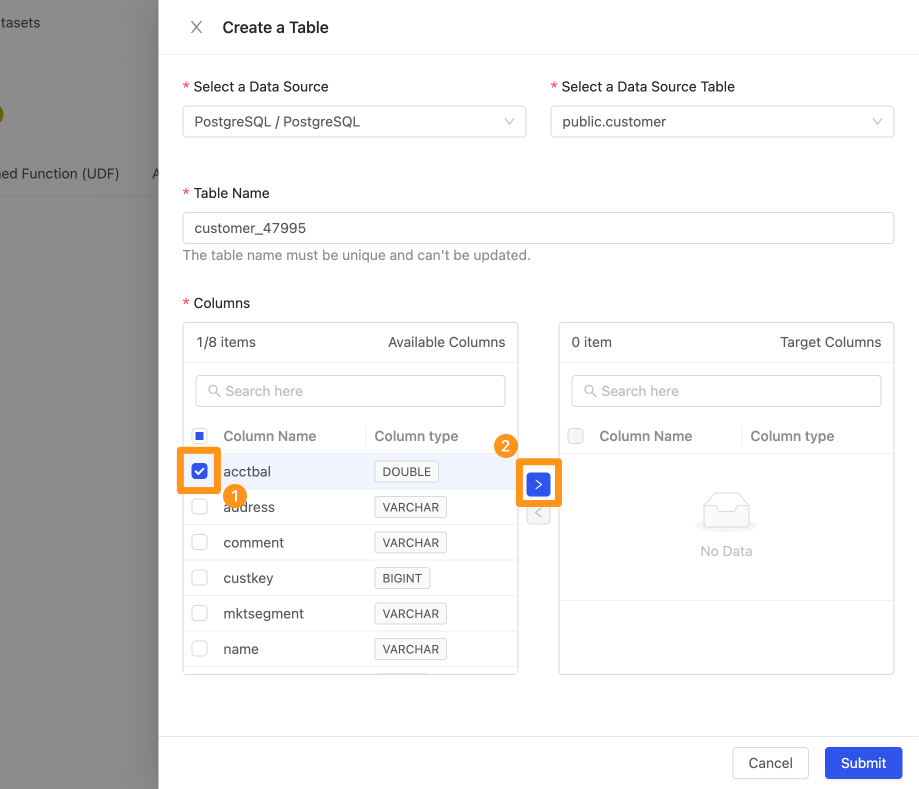
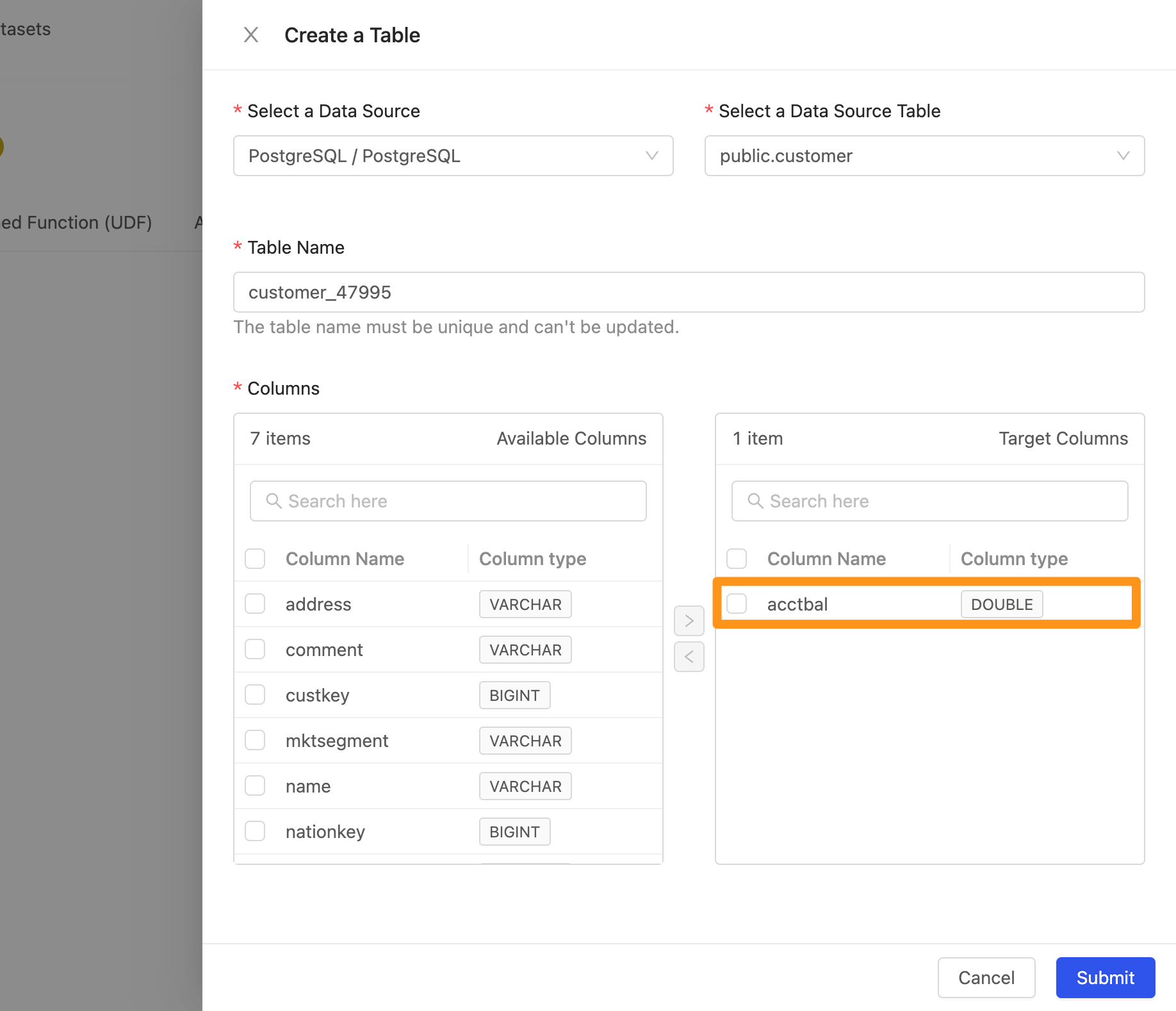
- 選取欄位,點擊 >,該 Column 會移動到右側,代表要此為要匯入工作區的資料欄位。
Step 3: 完成建立
點擊 Submit 送出,完成建立,將會在畫面中看到完成匯入的資料。
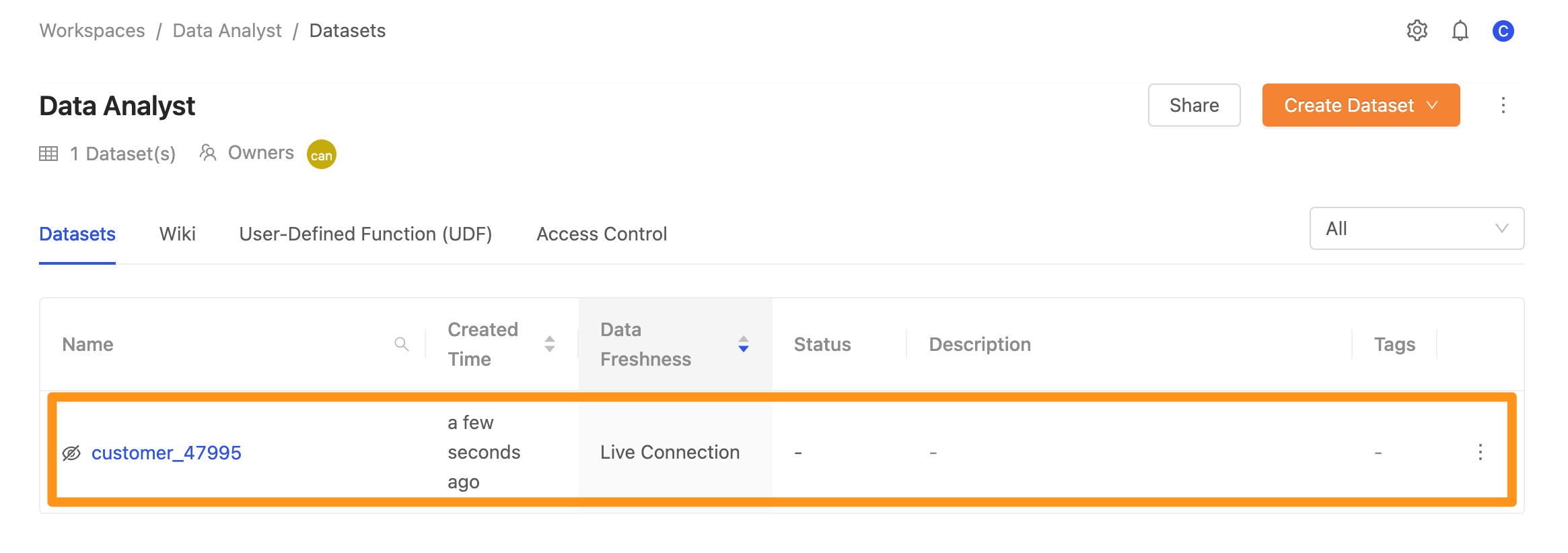
方法 2: 從其他工作區匯入
要使用此方法匯入時,使用者必須同時擁有這兩個工作區的使用權限才能執行。
Step 1: 進入工作區頁面
在 Datasets 分頁中,擊 Create Dataset 按鈕。點擊後會出現下拉選單,選擇 Create a Shared Table 按鈕。
Step 2: 設定從工作區匯入資料
選擇要從哪個工作區匯入哪個資料來源及其資料表與欄位。
- Select a Workspace : 選擇工作區
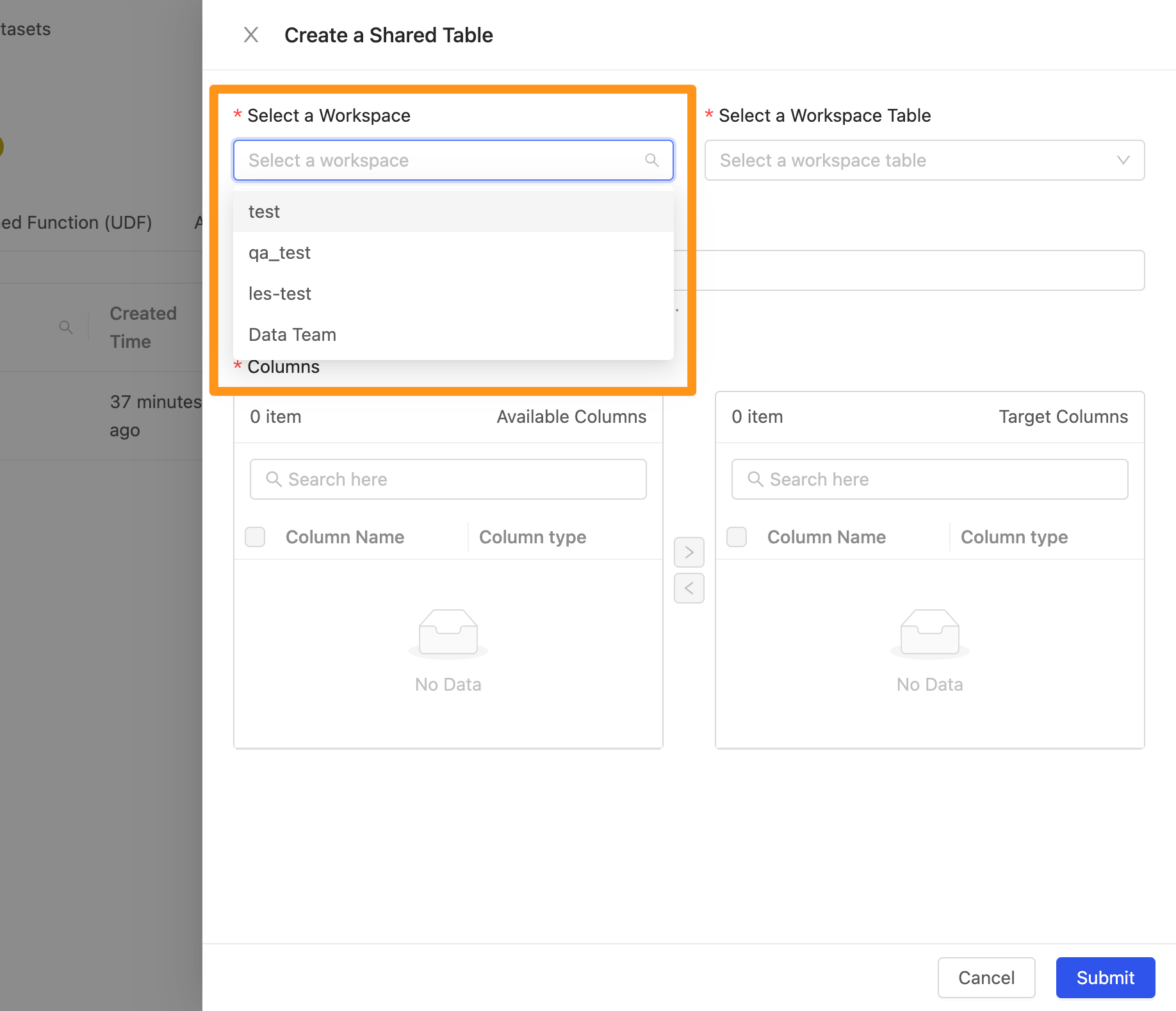
- Select a Workspace Table: 選擇工作區的資料
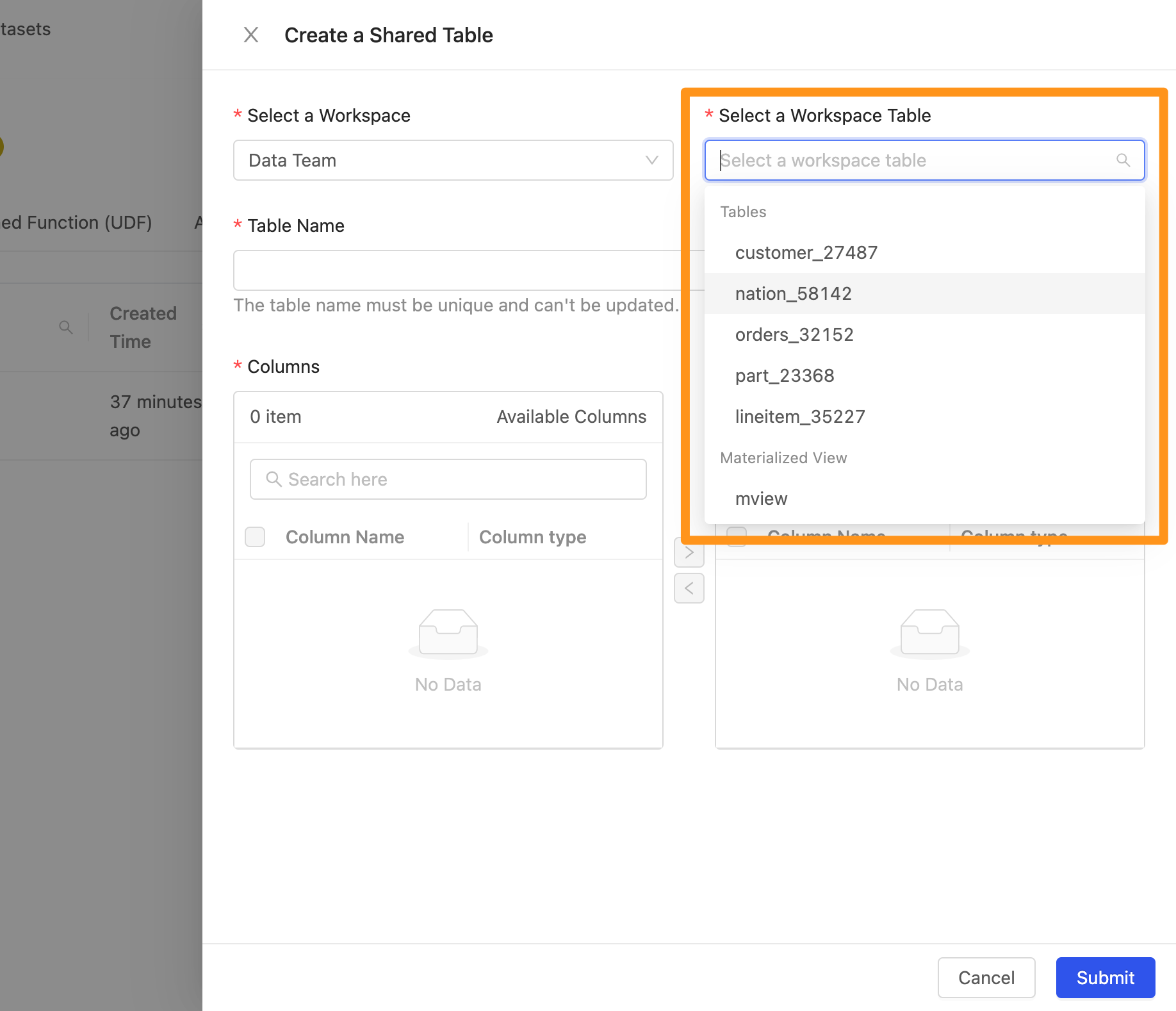
- Table Name : 新增 Table 的時候,系統會以資料表的名稱自動產生出一個唯一值的名稱,以避免 table 在名稱上面與其他的命名重複。
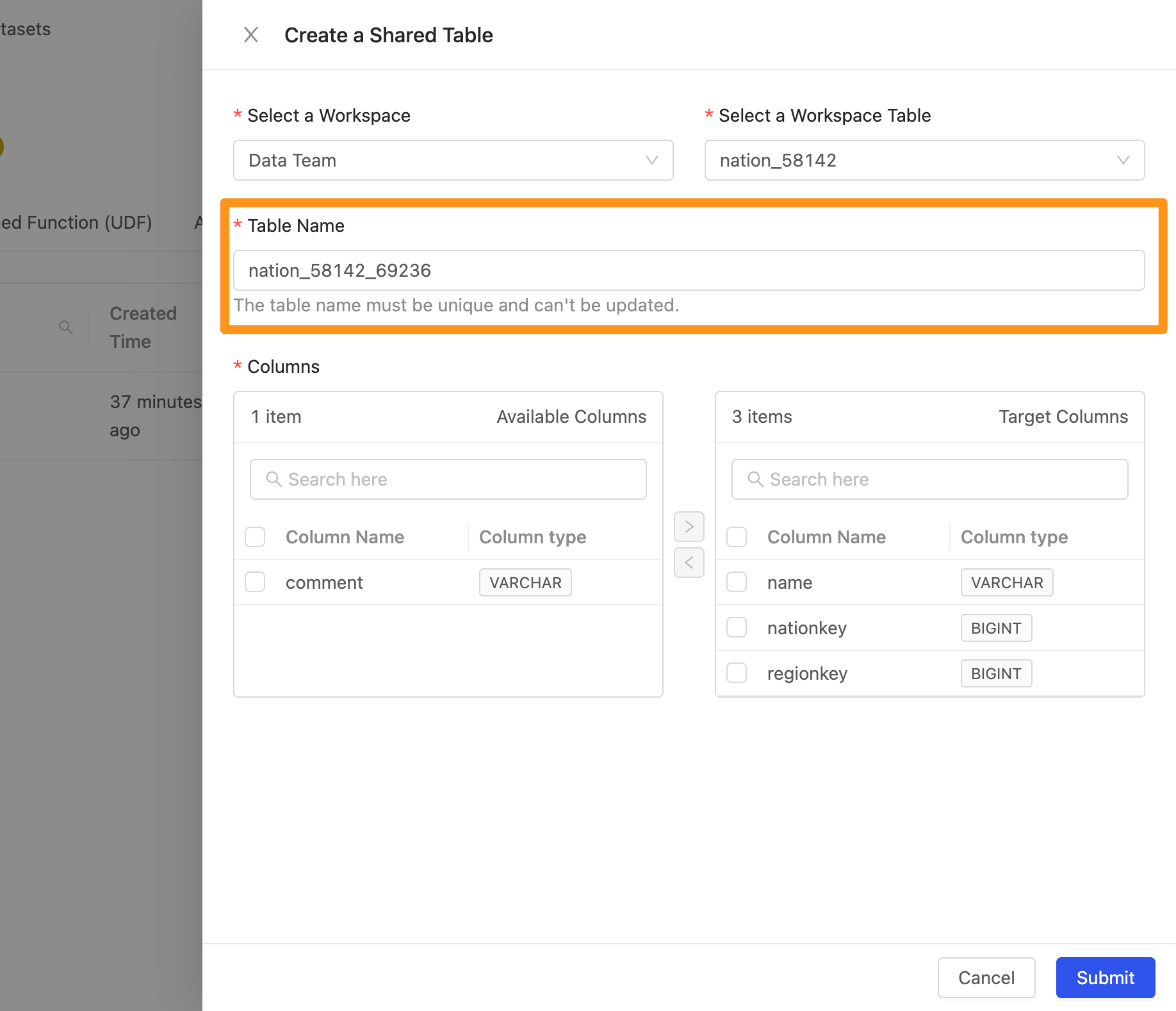
Step 3: 完成建立
點擊 Submit 送出,完成建立,將會在畫面中看到完成匯入的資料。
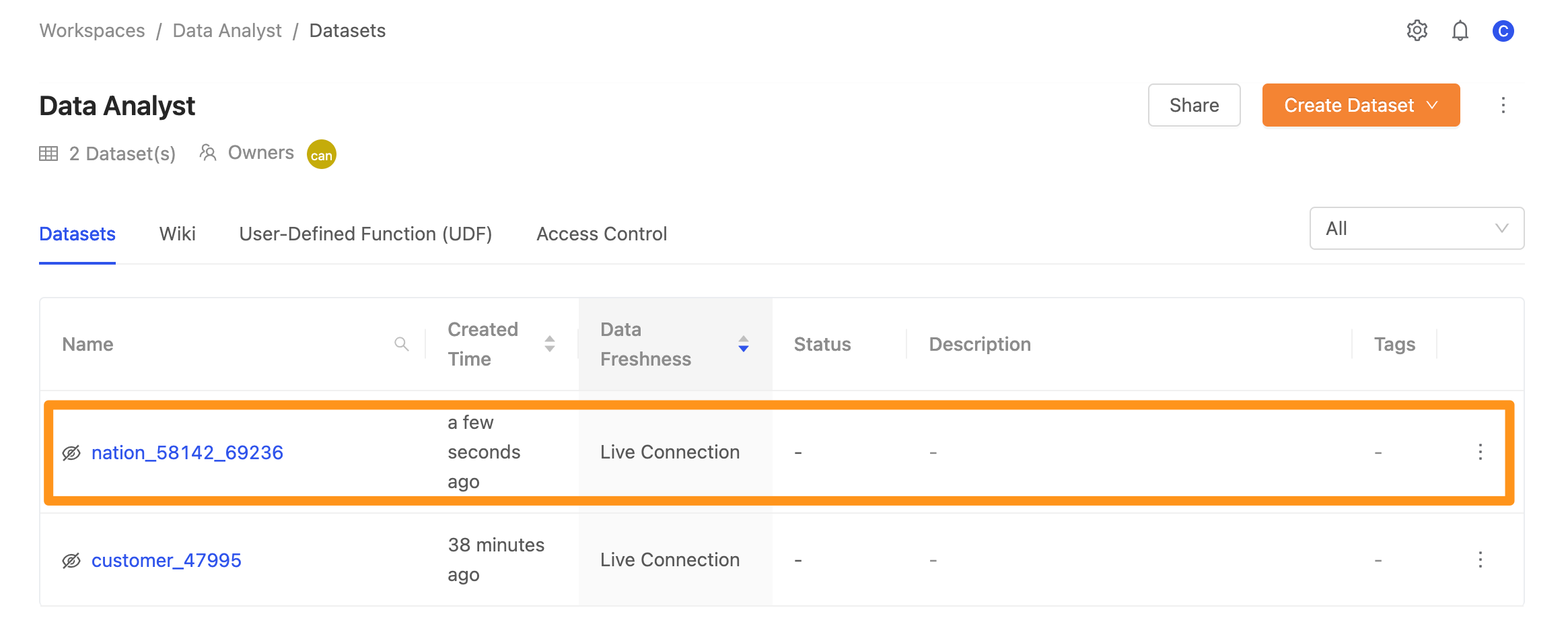
您可以在運用語意層管理資料使用權了解更多透過 Canner Enterprise 權控設計來管理工作區中不同成員角色資料使用權的方法。
使用 SQL Editor 整合、清理、運算分析資料
資料成功匯入至工作區後,你可以點擊左上角切換選單,選取 Analysis,即可以進入 SQL Editor 畫面。進行 SQL 查詢時,Canner Enterprise 運用標準 ANSI SQL 查詢進行需要的資料處理。
以下是 SQL Editor 的畫面簡介如下
- 代表目前所在的工作區,可以點擊 Switch 按鈕進行切換。
- 代表此工作快中所有可以使用的資料,並可以透過搜尋尋找
- 撰寫 SQL Statement 的區域
- 執行 SQL 的狀況與使用的資源
- 執行中以及歷史執行的 SQL 紀錄
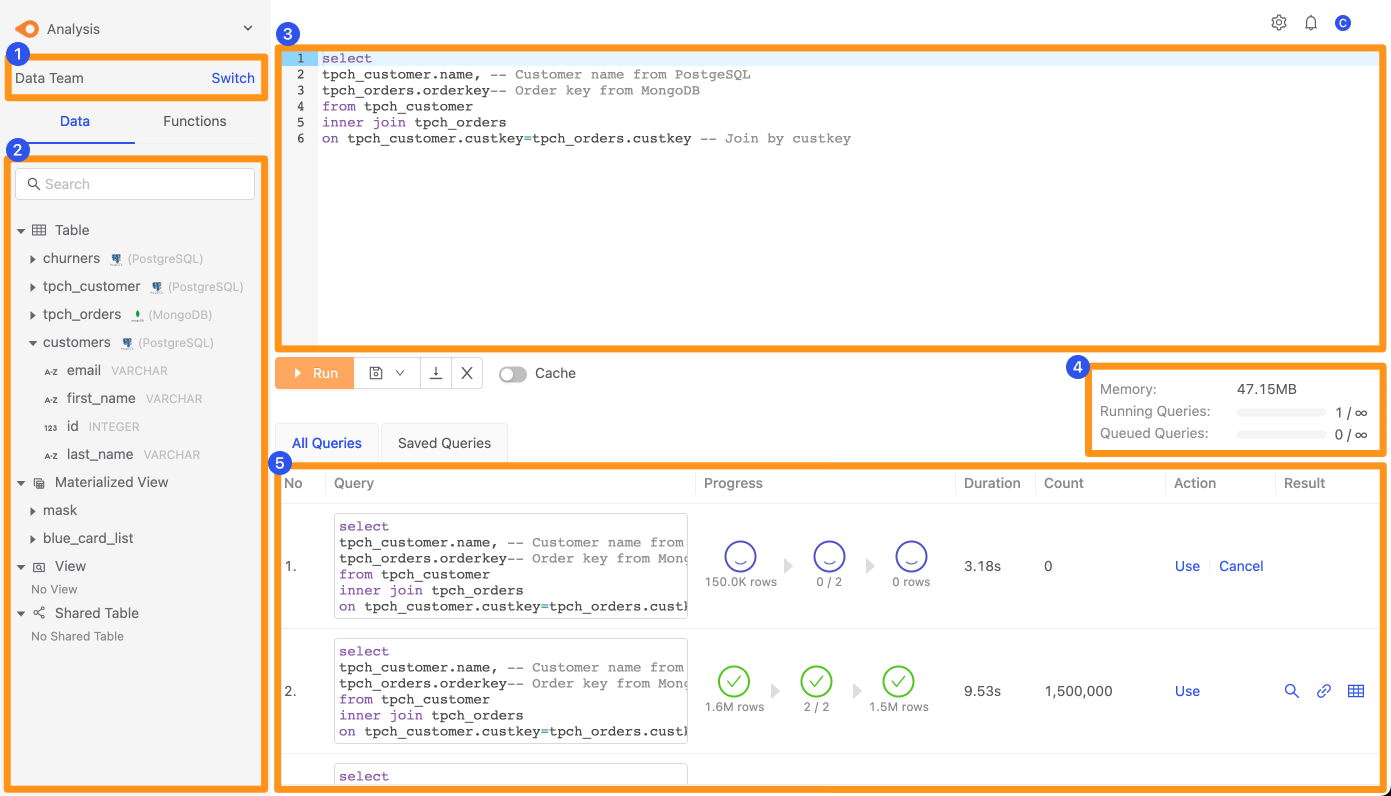
能夠使用的 Datasets
左側欄中可以看到在這個工作區您能使用的 Datasets,點擊三角形 Icon 可以展開查看有哪些 Datasets。
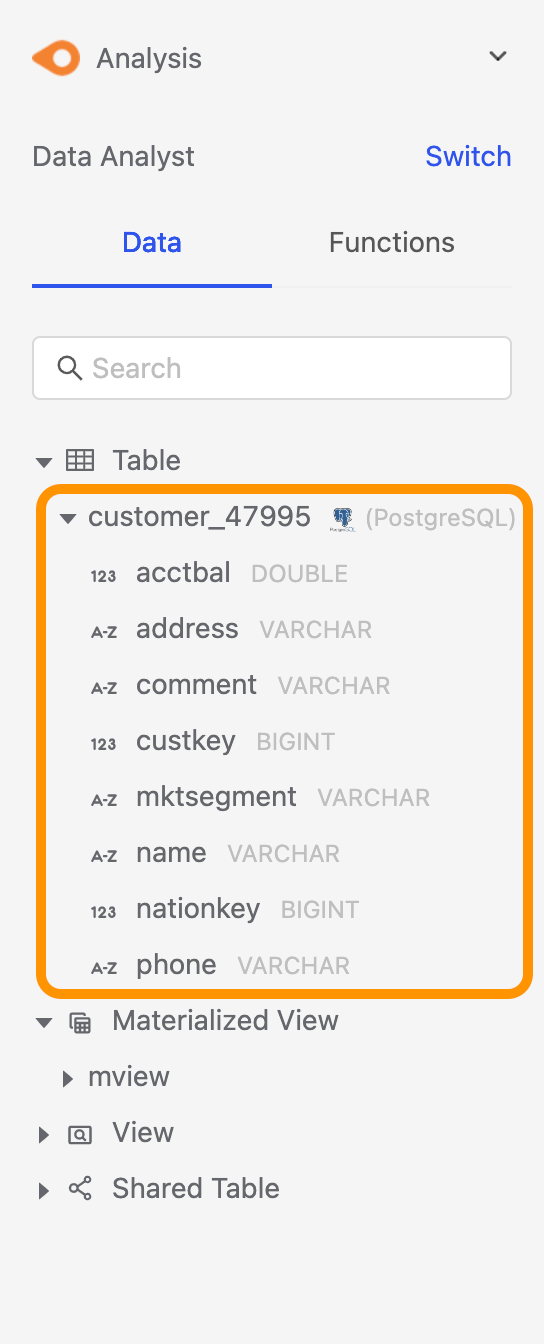
針對 Dataset 再進行點擊三角形 Icon,可以展開查看每個 column 的形態
執行 SQL
在 SQL Editor 您可以立即針對 SQL 進行查詢,就像是操作一個資料庫的感覺。以下針對相關欄位進行說明
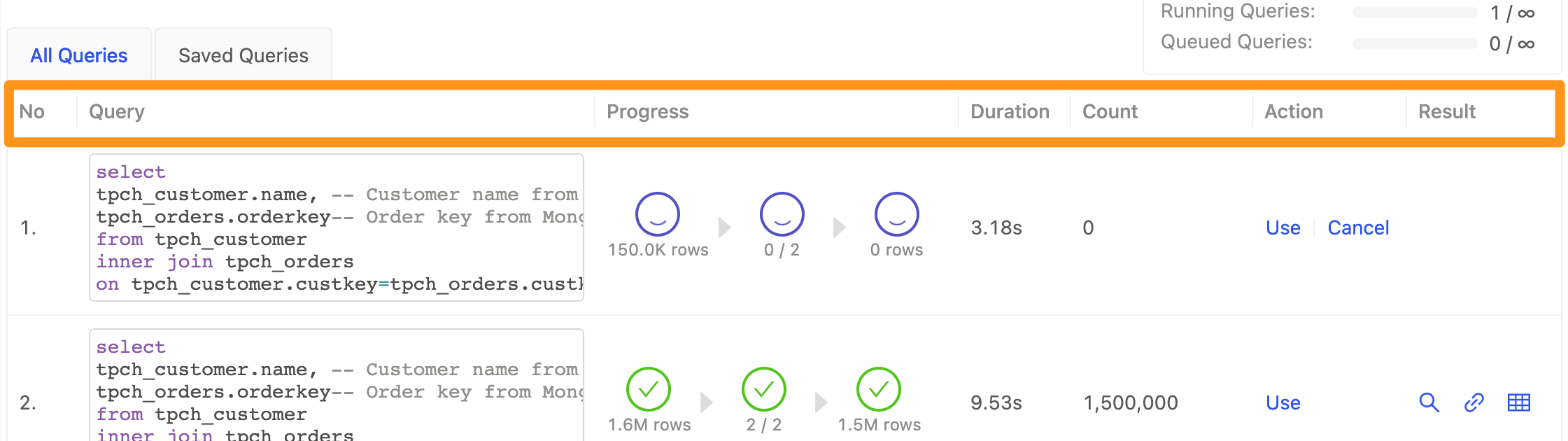
No: 代表執行 SQL 的編號Query: 每一次執行的 SQLProgress: 執行過程第一個藍色圓圈: 輸入資料筆數第二個藍色圓圈: 處理階段第三個藍色圓圈: 輸出資料筆數
Duration: 執行時間Count: 查詢結果筆數Action: 可執行的動作Use: 使用該 SQL 語句,點擊後會將 SQL Statement 帶入 Editor 中Cancel: 取消正在執行的 Query
Result: 針對執行結過進行以下動作- 查看 Query 執行結果
- 將資料下載成 CSV
- 將查詢結果轉存成 Materialized View
SQL 完成
在您得到您的數據結果時您會看到以下畫面。根據結果,你可以點擊圖中三種不同的 Icon 執行以下動作

- 放大鏡: 查看 query 的執行結果。
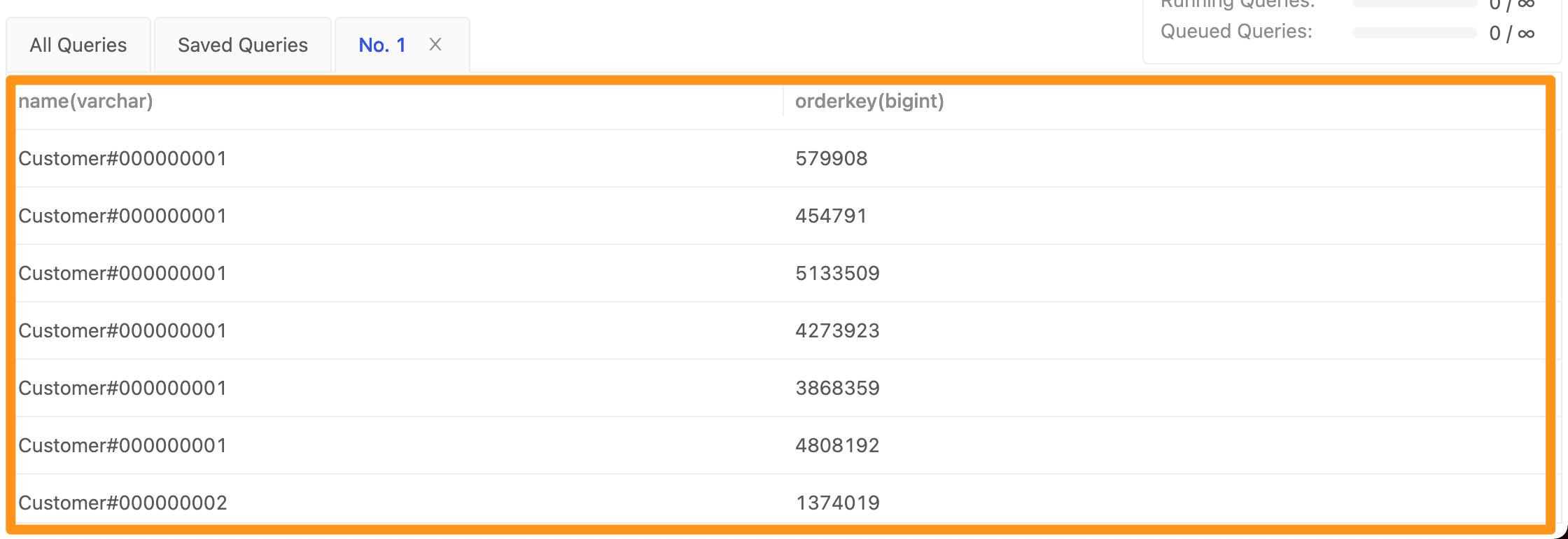
- 下載: 點擊下載按鈕後,將會把結果打包並下載成 CSV。
- 表格: 將查詢結果轉儲存成 Materialized View。
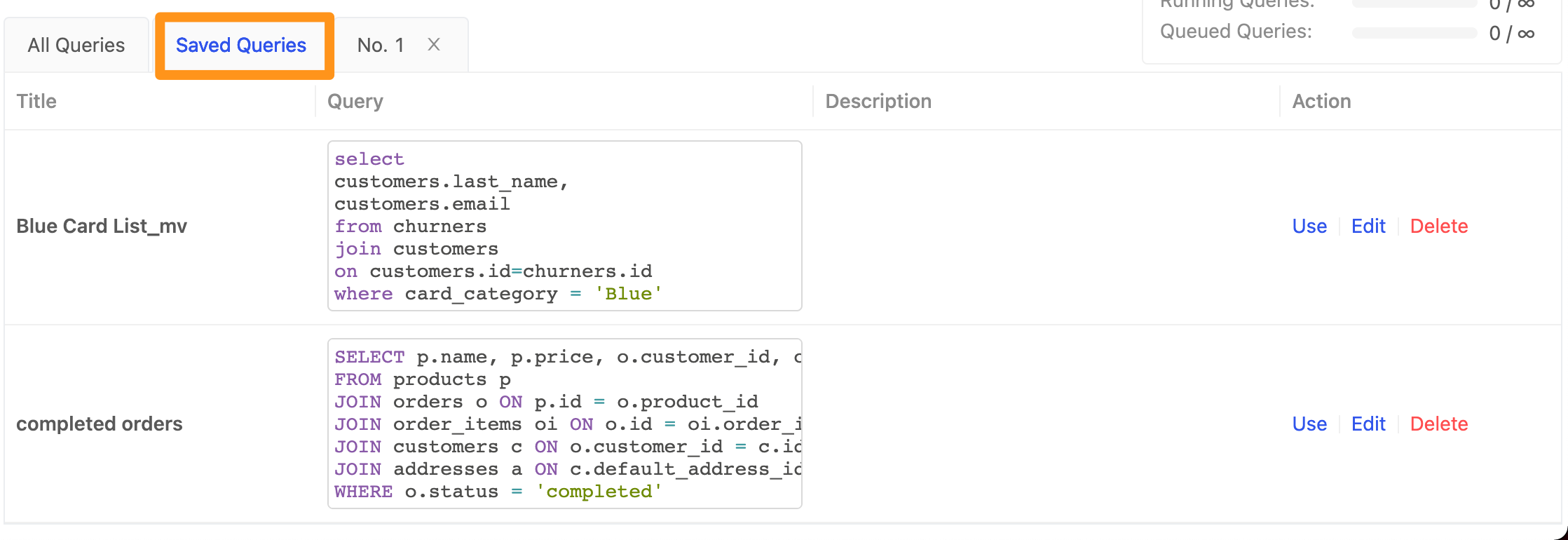
儲存常用的 SQL
您可以把組織內部常用的 SQL 存起來供同樣在這個工作區內的人能夠使用,注意您每個人的 SQL Editor 所執行的內容在同一個工作區裡面的其他人並無法看到您所下的 SQL,但是存在 Saved Queries 在同一個工作區的其他人也會看到!
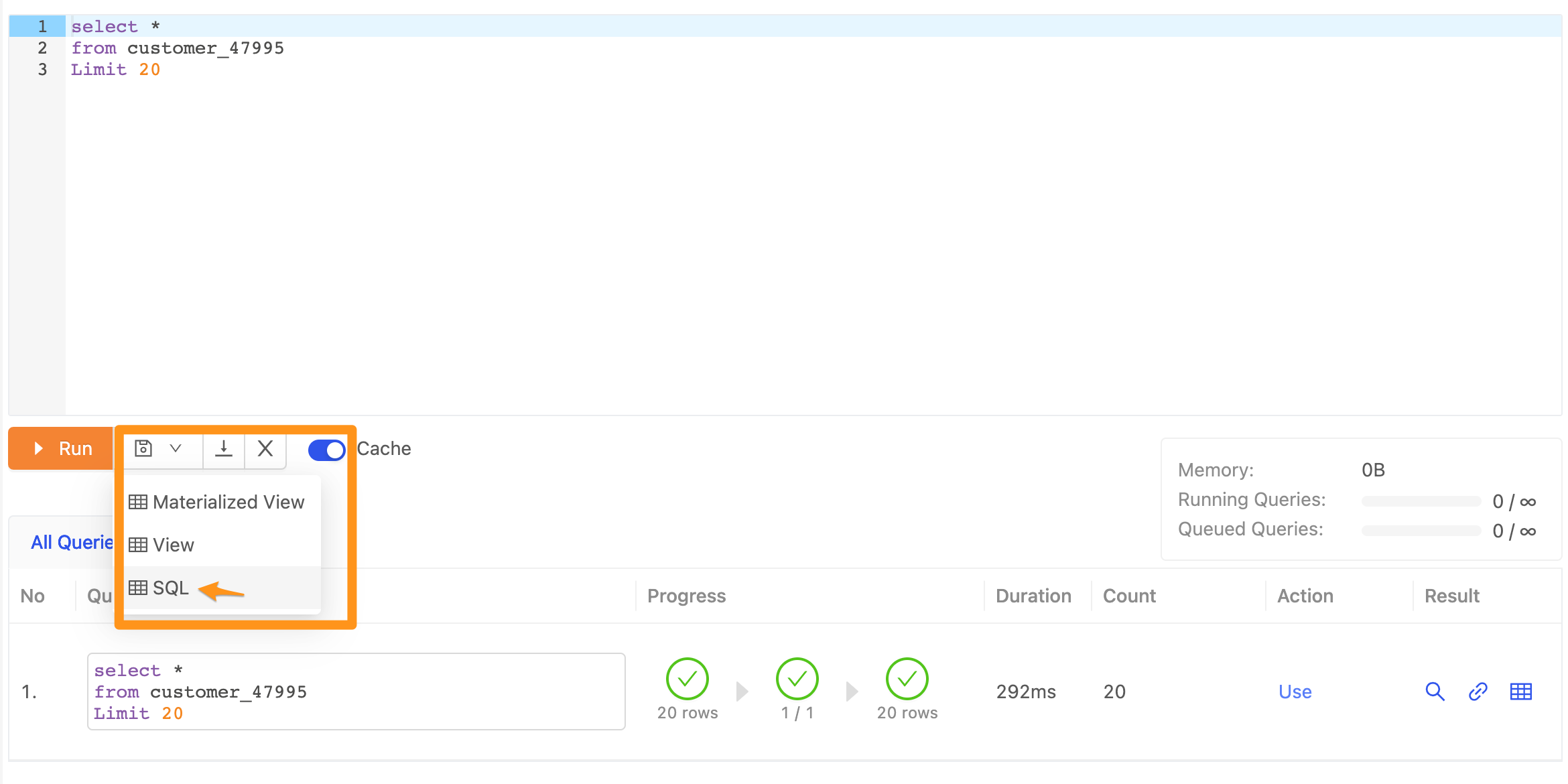
如何儲存常用的 SQL
點擊 SQL Editor 下方的儲存按鈕,並選取 SQL。
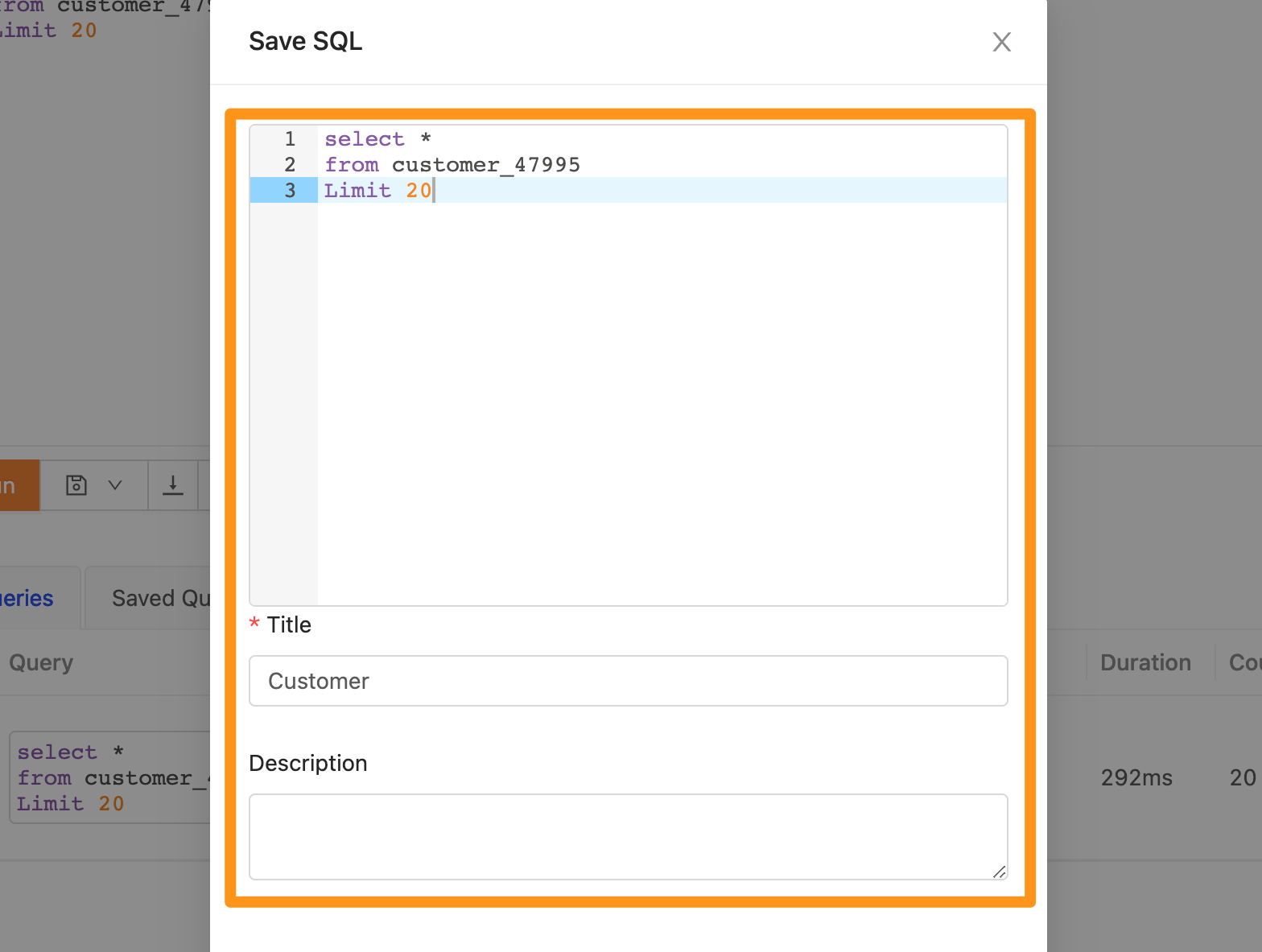
在儲存的表單,填寫 SQL Statement 後按儲存即可完成。
輸出資料至應用端
在工作區中將需要分析的資料調用處理後,Canner Enterprise 提供多種輸出端口,讓您可以針對不同應用端最佳化資料對接方式:
- 輸出下載為 CSV 檔
當在 SQL Editor 查詢的結果想要下載成 CSV 的話,可以在下圖中結果欄,按下下載 CSV ,系統就會開始打包原本的結果成 CSV 檔案。

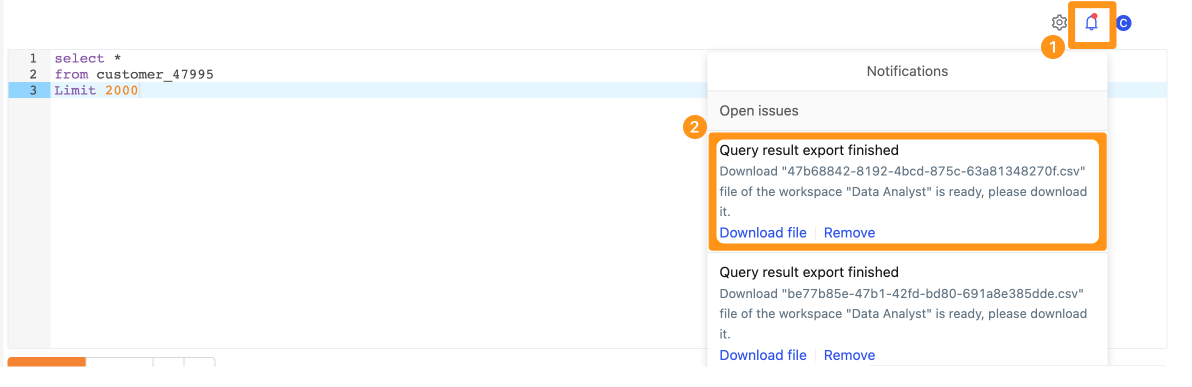
- 當打包完成後,您需要按右上角的小鈴鐺,您就可以看到準備好的下載檔案。按一下 "Download" 就會開始進行下載,如下圖。
- 連結 BI 工具
- Restful API 輸出
- Python SDK 輸出
- Scala SDK 輸出
- JDBC 輸出
- ODBC 輸出
- PostgresSQL Wire Protocol 輸出