FAQ
關於產品支援
Q: Canner Enterprise 可以提供客製化的 SLA 嗎?
有的,Canner 提供企業基本的 SLA 以及進階企業級的 SLA 不論是您是發佈在地端或雲端版本,您可以直接接觸我們的業務了解詳情 sales@cannerdata.com。
關於 SQL Engine
Q: 系統當到系統限制時是會暫停、還是暫緩執行?
目前 Canner Enterprise 是會把所需當次的 SQL 所需運算的資料拉到 RAM,如單次工作資料量超過負荷就會 out of memory,就需要額外購買更大 License。
Q: 虛擬資料庫中的欄位改變怎麼辦?
在 Canner Enterprise 有個 Schema 的 detector 會定期追蹤系統中的 schema 異動,如有異動會通知 Admin 改變的項目,讓 Admin 能夠去追蹤哪些欄位有異動以及影響到哪些虛擬資料庫的欄位。
Q: Canner Enterprise 使用的 SQL 語法?
Canner 是使用標準 ANSI SQL
關於資料儲存
Q: Canner Enterprise 可以建置在企業內部的雲嗎?
Canner Enterprise 不論是在雲或是地端,都是建置在企業的雲以及伺服器中,所有資料都不會出企業內部,資料也都保留於企業內。
Q: Canner Enterprise 整理好的資料落地放在哪?
- 地端:Canner Enterprise 會存在 SSD 裡面
- 雲端:Canner Enterprise 會存在 Cloud Data Lake 中像是 S3 (AWS), Blob storage (Azure)
Q: 有 Cache 功能嗎?Cache 多久清一次?
Canner Enterprise 有 Cache 功能,Cache 目前 Default 為 7 天。如大型企業可以客製清理的時間。
關於資料整合
Q: Canner Enterprise 可串 Source API 嗎?
目前不支援直接連結 API 接口,但您可以把 API 用傳統方式存到資料庫中再接過來即可。
Q: 使用 Canner Enterprise 如果要如果要寫回去資料庫呢?
您能夠透過 ETL 軟體把 Canner Enterprise 當作一個 source 在使用 ETL 工具把資料回存到資料庫或是 Storage 中。
Q: MongoDB 可以 Query 到幾層?
簡而言之,可以到很深入到無窮層的 Querying。
我們已以下資料為例

{
"_id":"6192badb8b480205e9484a33",
"info":{
"name":"william",
"age":"30",
"friends":[
{
"name":"ken",
"age": 30
"home":{
"city":"Taipei",
"members":[
{
"name":"Grace",
"relationship":"mother"
},
{
"name":"PY",
"relationship":"father"
}
]
}
},
{
"name":"kevin",
"age": 35
"home":{
"city":"Tainan"
}
}
]
}
}
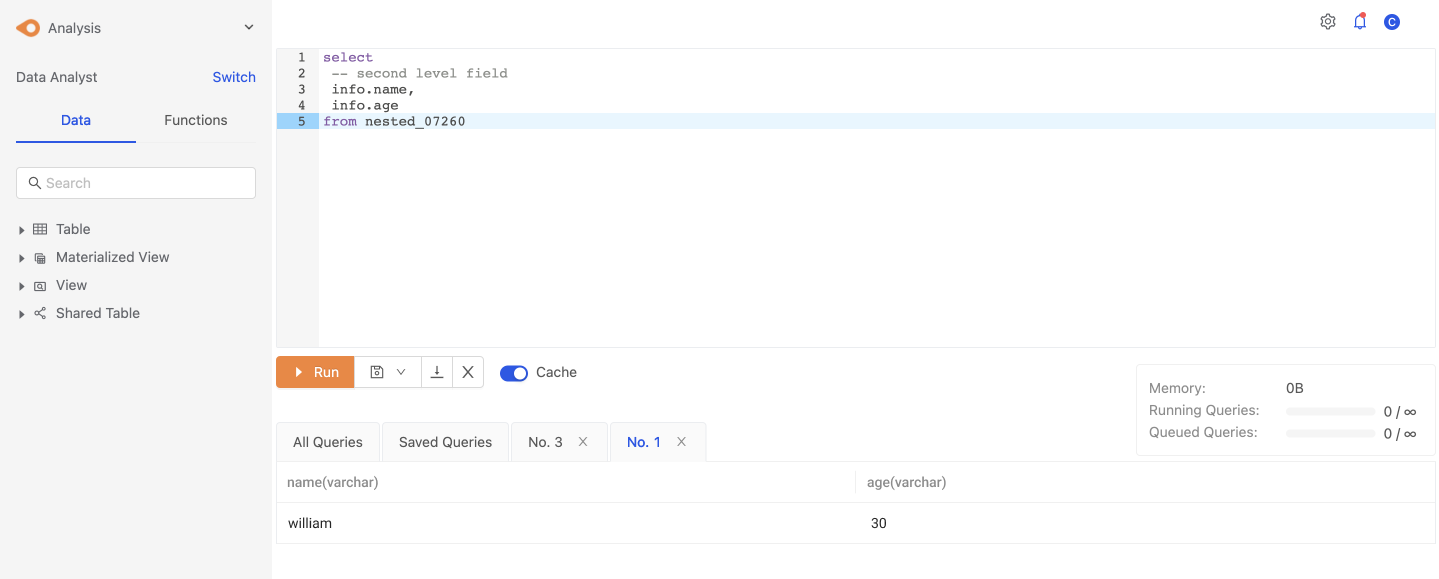
我們可以拆解到 nested 相當深層的欄位,以上述資料來說,以下範例提供基本的第二層欄位讀取
select
-- 第二層欄位
info.name,
info.age,
info.friends
from nested_07260
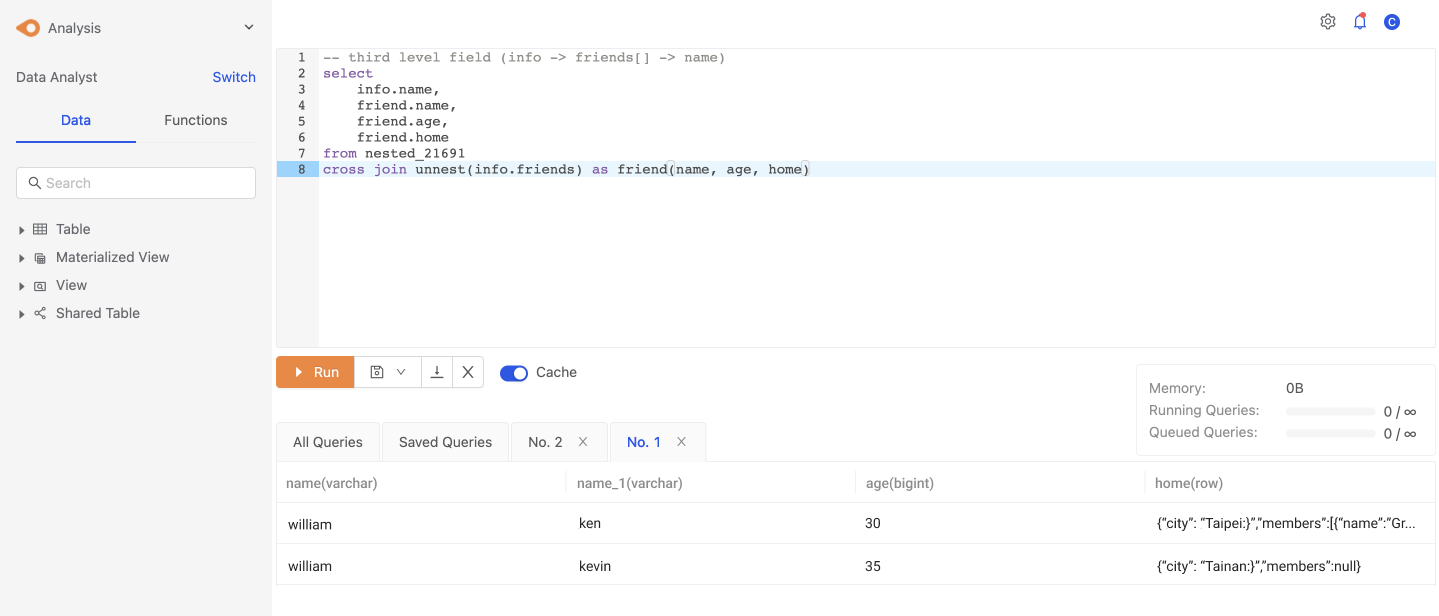
接下來到第三層欄位中,若有 array of object,常見的情境是希望可以攤平成 rows,後續不管是 join, where 等語法,或是任何 aggregation 等運算都可以延伸,這邊介紹 UNNEST 這個語法
(UNNEST: https://docs.cannerdata.com/product/sql/sql_select/#unnest)
-- 拆解第三層欄位 (info -> friends[] -> name)
select
info.name,
friend.name,
friend.age,
friend.home
from nested_21691
cross join unnest(info.friends) as friend(name, age, home)
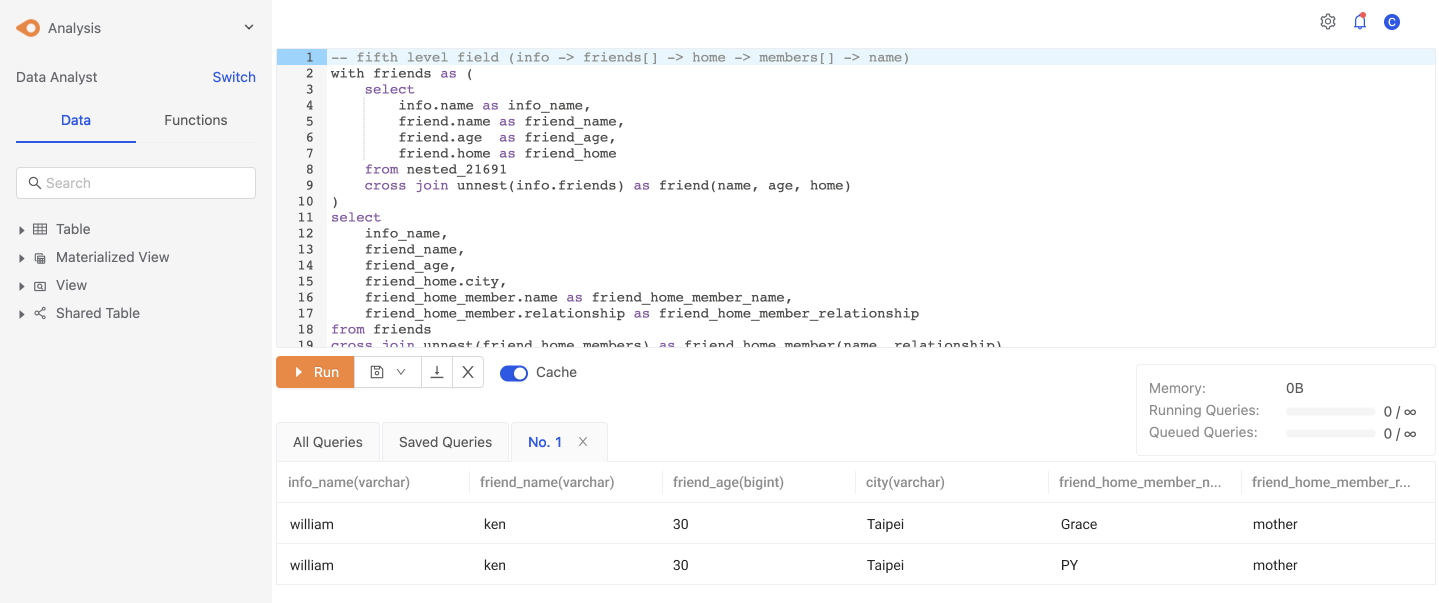
我們可以再深入到第五層欄位,以下範例我們搭配 CTE (with statement),使用 unnest 語法把第五層中 nested array 中的欄位拉到第一層做使用
-- 拆解第五層欄位 (info -> friends[] -> home -> members[] -> name)
with friends as (
select
info.name as info_name,
friend.name as friend_name,
friend.age as friend_age,
friend.home as friend_home
from nested_21691
cross join unnest(info.friends) as friend(name, age, home)
)
select
info_name,
friend_name,
friend_age,
friend_home.city,
friend_home_member.name as friend_home_member_name,
friend_home_member.relationship as friend_home_member_relationship
from friends
cross join unnest(friend_home.members) as friend_home_member(name, relationship)
理論上,一般情境使用下很難碰到 Canner Enterprise 在 CTS 上的系統限制,所以可以到相當深層欄位的存取,但在實務上,過於 nested 的欄位若需要大量的使用 CTS,仍會造成 performance 上些許的影響。
Q: MongoDB 是巢狀,user 可否針對巢狀內容做 Search?可撈巢狀裡面的資料嗎?
Canner Enterprise 可處理複雜結構,像是 array, object,例如 https://docs.atlas.mongodb.com/sample-data/sample-analytics/#sample_analytics.transactions 這邊的 sample dataset 可以用下面這種方式 query
select
transactions[1].date
from transactions_96448
where any_match(transactions, t -> t.amount > 7000)
找出 transactions 這個 array-of-object field 中有任何 element 的 amount > 7000 的 row,並取出第一筆交易的 date
可以參考 Array document: https://docs.cannerdata.com/product/sql/functions/array