Troubleshooting
Here are potential issues you may encounter during the installation process:
- Deployment/ingress-nginx-controller-nginx-public Can't Be Ready Before Timeout : This section explains how to resolve the deployment timeout issue caused by the absence of the "ingress-nginx-controller-nginx-public-admission" secret. This part provides steps for deleting admission jobs, reapplying cannerflow-deployer, and ensuring the creation of the required secret.
Here are potential issues you may encounter during the usage process:
- K3S Certificates Expired : This section guides you on resolving the issue where most pods are stuck in the init status, and kubectl describe pod indicates "no IP addresses available in the network" in the events.
- Keycloak Realm Does Not Match : This section addresses an issue where pods remain stuck at the init status due to IP leaks in the CNI (flannel) layer.
- Web UI Stuck at Loading : This section addresses the Web UI loading issue with failed GraphQL requests and Keycloak errors. Likely caused by a sync failure in the User Federation. Resolve by fixing the SSO server sync (especially LDAP) or remove outdated user federation from Keycloak
Deployment/ingress-nginx-controller-nginx-public Can't Be Ready Before Timeout
What You Will See
You’ll notice that the deployment failed with the following messages:
Error: Deployment/ingress-nginx-controller-nginx-public can't be ready before timeout
at p_retry_1.default.retries (/home/ec2-user/.nvm/versions/node/v12.22.12/lib/node_modules/@canner/src/k8s/apiClient.ts:108:24)
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:97:5)
at RetryOperation._fn (/home/ec2-user/.nvm/versions/node/v12.22.12/lib/node_modules/@canner/cannerflow-deployer/node_modules/p-retry/index.js:50:12) {
data: null,
isBoom: true,
isServer: true,
output: {
statusCode: 500,
payload: {
statusCode: 500,
error: 'Internal Server Error',
message: 'An internal server error occurred'
},
headers: {}
},
reformat: [Function],
typeof: [Function: internal],
attemptNumber: 101,
retriesLeft: 0
}
disconnect from mongo server ...
Exit with error
When you kubectl describe po <ingress-nginx-controller-nginx-public-pod-name> -n ingress-nginx, you’ll see from the following events that secret "ingress-nginx-controller-nginx-public-admission" not found
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 36m default-scheduler Successfully assigned ingress-nginx/ingress-nginx-controller-nginx-public-5596bf746c-xlxk8 to ip-172-31-30-167.ap-northeast-1.compute.internal
Warning FailedMount 23m (x2 over 32m) kubelet Unable to attach or mount volumes: unmounted volumes=[webhook-cert], unattached volumes=[ingress-nginx-token-kd76l webhook-cert]: timed out waiting for the condition
Warning FailedMount 18m (x6 over 34m) kubelet Unable to attach or mount volumes: unmounted volumes=[webhook-cert], unattached volumes=[webhook-cert ingress-nginx-token-kd76l]: timed out waiting for the condition
Warning FailedMount 18m (x17 over 36m) kubelet MountVolume.SetUp failed for volume "webhook-cert" : secret "ingress-nginx-controller-nginx-public-admission" not found
Warning FailedMount 10m (x2 over 15m) kubelet Unable to attach or mount volumes: unmounted volumes=[webhook-cert], unattached volumes=[ingress-nginx-token-kd76l webhook-cert]: timed out waiting for the condition
Warning FailedMount 97s (x5 over 13m) kubelet Unable to attach or mount volumes: unmounted volumes=[webhook-cert], unattached volumes=[webhook-cert ingress-nginx-token-kd76l]: timed out waiting for the condition
Warning FailedMount 52s (x16 over 17m) kubelet MountVolume.SetUp failed for volume "webhook-cert" : secret "ingress-nginx-controller-nginx-public-admission" not found
What Happened
Some issue (possibly network-related) caused the ingress-nginx-admission-create and ingress-nginx-admission-patch jobs to fail, resulting in the failure to create the secret "ingress-nginx-controller-nginx-public-admission".
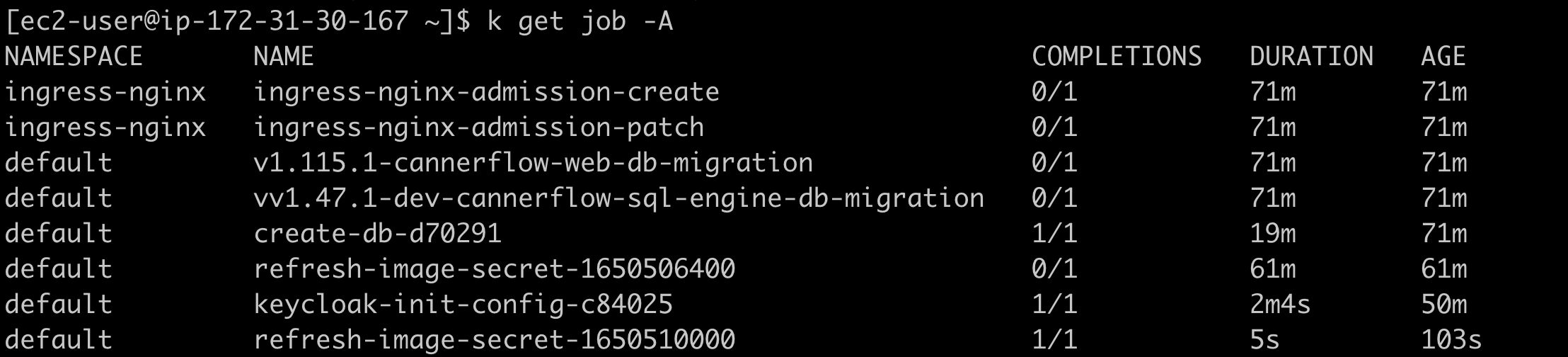
How to Resolve
- Delete the jobs
ingress-nginx-admission-createandingress-nginx-admission-patch.
[ec2-user@ip-172-31-30-167 ~]$ kubectl delete job ingress-nginx-admission-create -n ingress-nginx
job.batch "ingress-nginx-admission-create" deleted
[ec2-user@ip-172-31-30-167 ~]$ kubectl delete job ingress-nginx-admission-patch -n ingress-nginx
job.batch "ingress-nginx-admission-patch" deleted
- Reapply the cannerflow-deployer.
- Check if the secret
ingress-nginx-controller-nginx-public-admissionis created. - Wait for the
ingress-nginx-controller-nginx-publicdeployment to succeed.
K3S Certificates Expired
What You'll See
Kubectl shows the following message:
Unable to connect to the server: x509: certificate has expired or is not yet valid
What Happened
K3s generates internal certificates with a 1-year lifetime. Restarting the K3s service automatically rotates certificates that expired or are due to expire within 90 days. However, in K3s version 1.18, there is an issue causing the system to fail to rotate certificates automatically, requiring manual intervention.
How to Resolve
Check the expiration date to ensure it has expired.
openssl s_client -connect localhost:6443 -showcerts < /dev/null 2>&1 | openssl x509 -noout -enddateDelete cached certificates and restart services.
kubectl --insecure-skip-tls-verify=true delete secret -n kube-system k3s-serving
sudo systemctl stop k3s.service
sudo mv /var/lib/rancher/k3s/server/tls/dynamic-cert.json /var/lib/rancher/k3s/server/tls/dynamic-cert.json.bak
sudo systemctl start k3s.service
References:
- Expired K3s Certificates Are Not Automatically Rotated Causing Connection Issues (ibm.com)
- Unable to Connect to the Server: x509: Certificate Has Expired or Is Not Yet Valid · Issue #3047 · k3s-io/k3s (github.com)
- How to Renew Cert Manually? - k3s, k3OS, and k3d - Rancher Labs
Keycloak Realm Does Not Match
What You Will See
You'll notice that most pods stuck at the init status. When you kubectl describe pod, you'll see no IP addresses available in the network in the events.
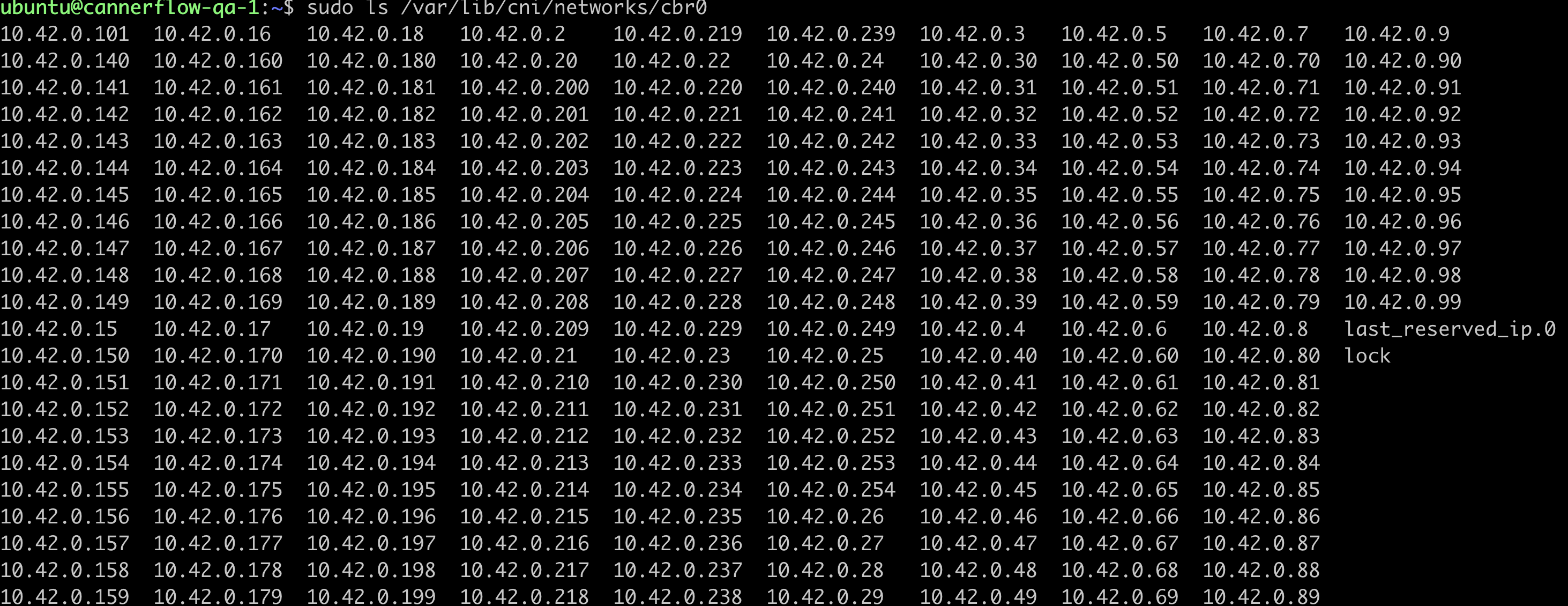
What Happened
There seem to be IP leaks at the CNI (flannel) level. When you run sudo ls /var/lib/cni/networks/cbr0, you'll see all IPs listed here are occupied and not released even though they're not used by pods.
How to Resolve
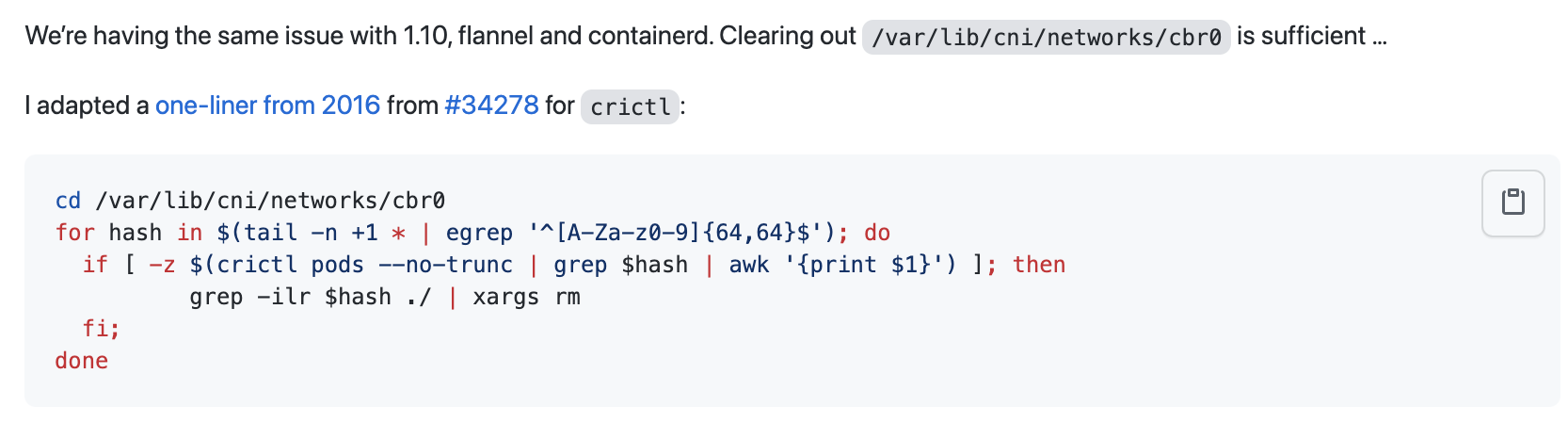
Run the following with superuser privileges:
cd /var/lib/cni/networks/cbr0
for hash in $(tail -n +1 * | egrep '^[A-Za-z0-9]{64,64}$'); do if [ -z $(crictl pods --no-trunc | grep $hash | awk '{print $1}') ]; then grep -ilr $hash ./ | xargs rm; fi; done
(Refer to source)
References:
- https://stackoverflow.com/questions/42450386/kubernetes-frequently-gets-error-adding-network-no-ip-addresses-available-in
- https://github.com/kubernetes/kubernetes/issues/57280
Web UI Stuck at Loading
What You'll See
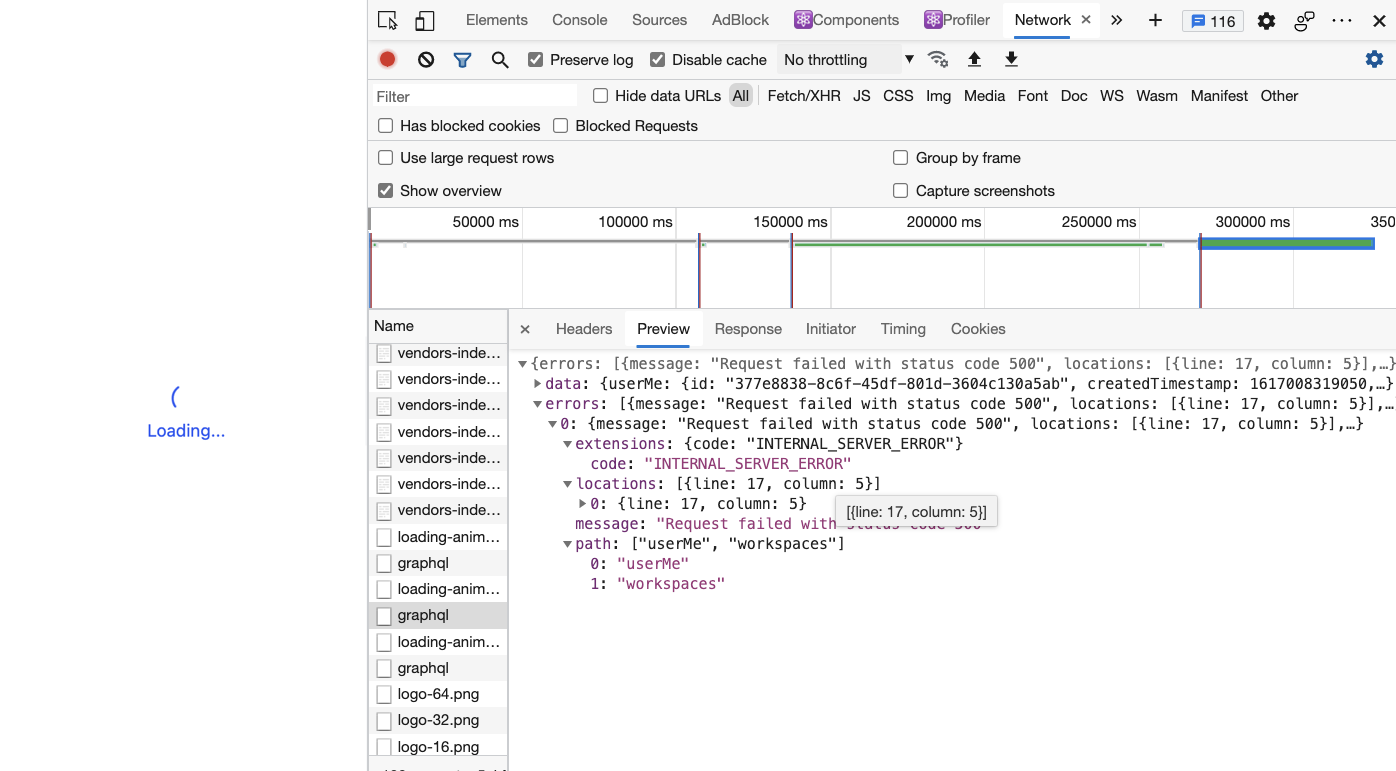
Web UI stuck at loading, and you'll notice that GraphQL requests like userMe and workspaces failed.
From backend logs, your request to Keycloak failed.
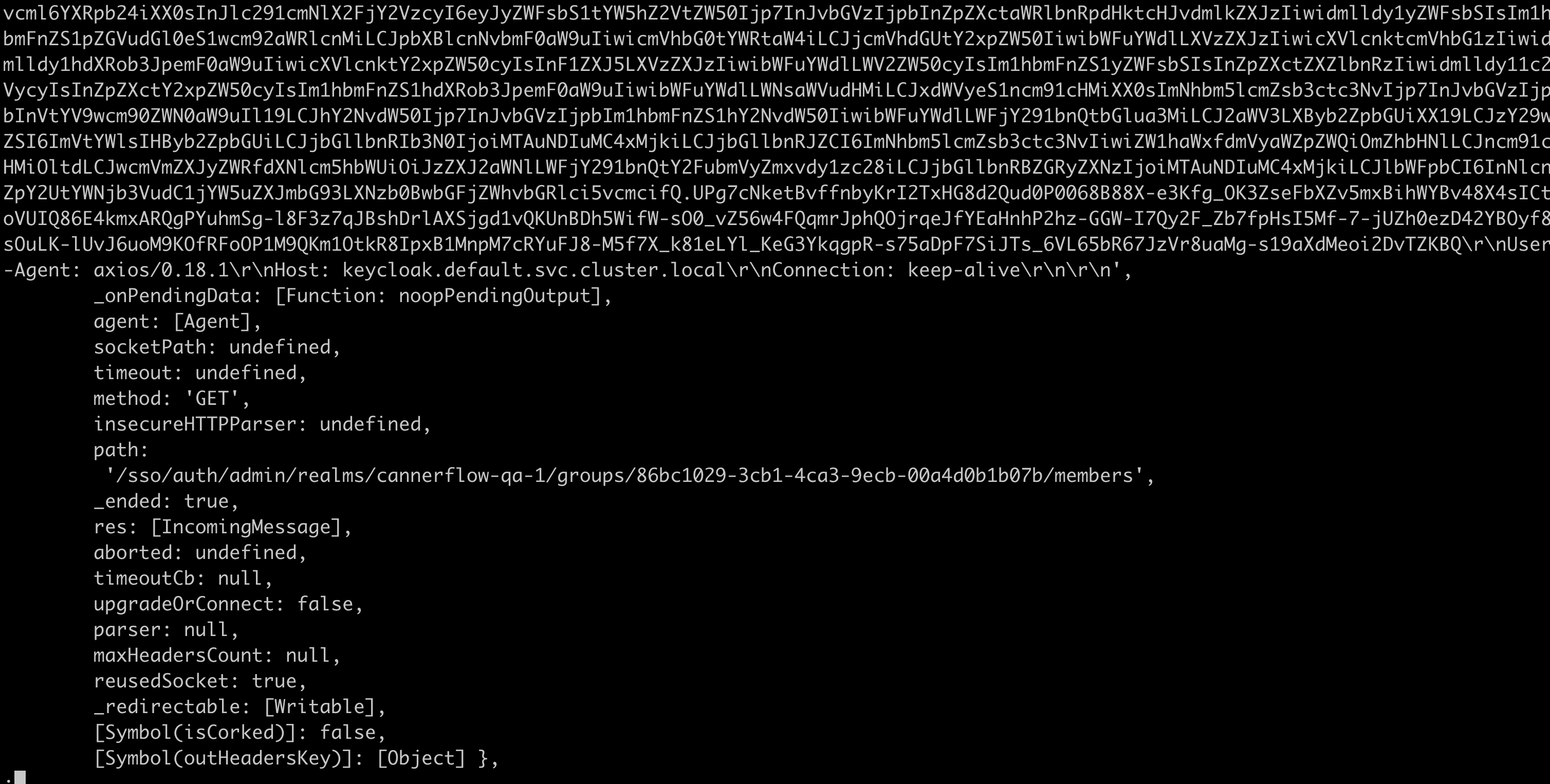
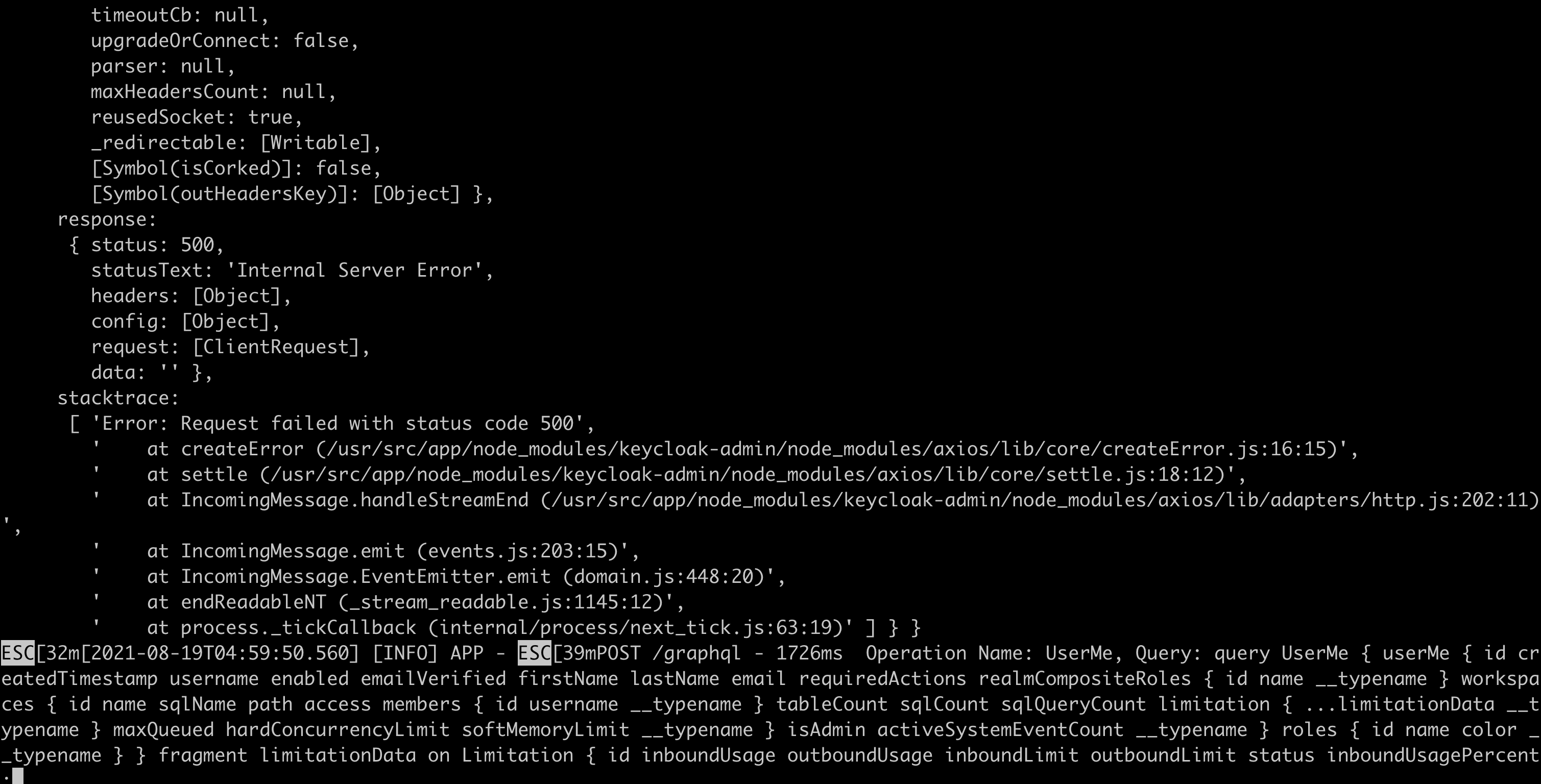
What Happened
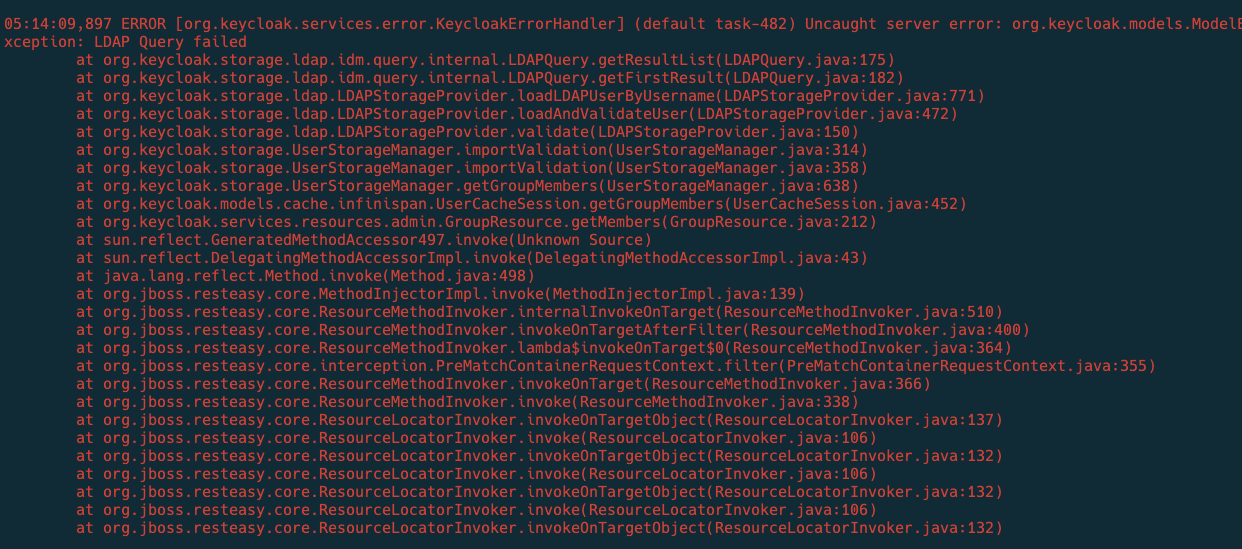
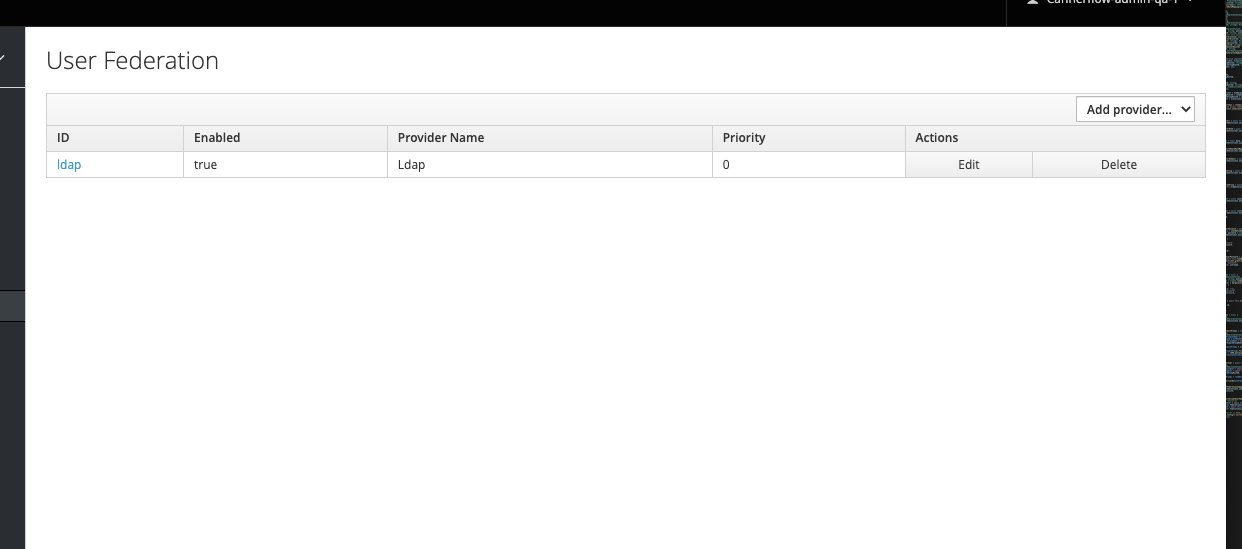
It's possible that Keycloak is having issues responding to requests because the User Federation sync failed.
How to Resolve
- Identify and fix the cause of the SSO (LDAP in this case) server sync failure.
- If the user federation is outdated and can be deleted, you can simply remove it from Keycloak.